
Если вам по работе или учёбе приходится погружаться в океан цифр и искать в них подтверждение своих гипотез, вам определённо пригодятся эти техники работы в Microsoft Excel. Как их применять — показываем с помощью гифок.

Тренер Учебного центра Softline с 2008 года.
1. Сводные таблицы
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение.
Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице. « Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы. При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
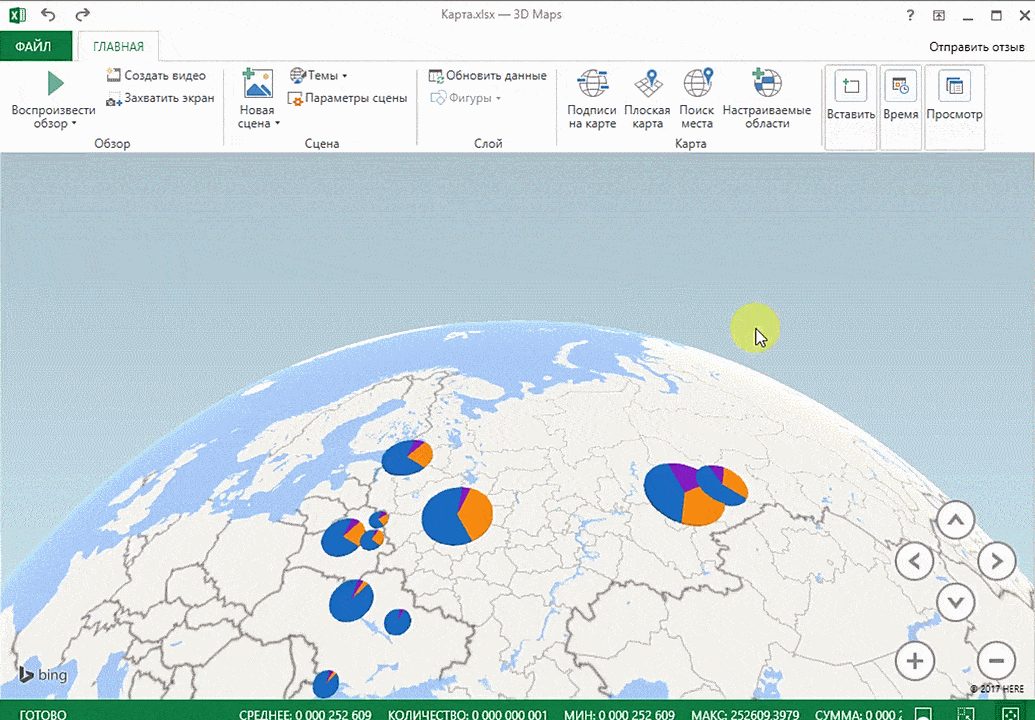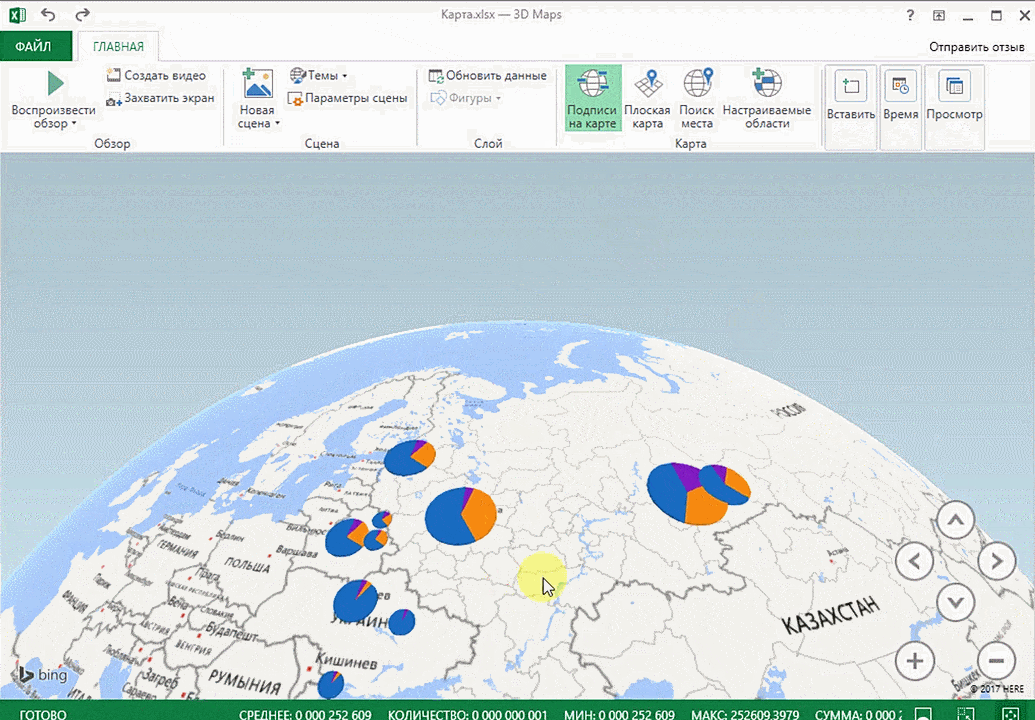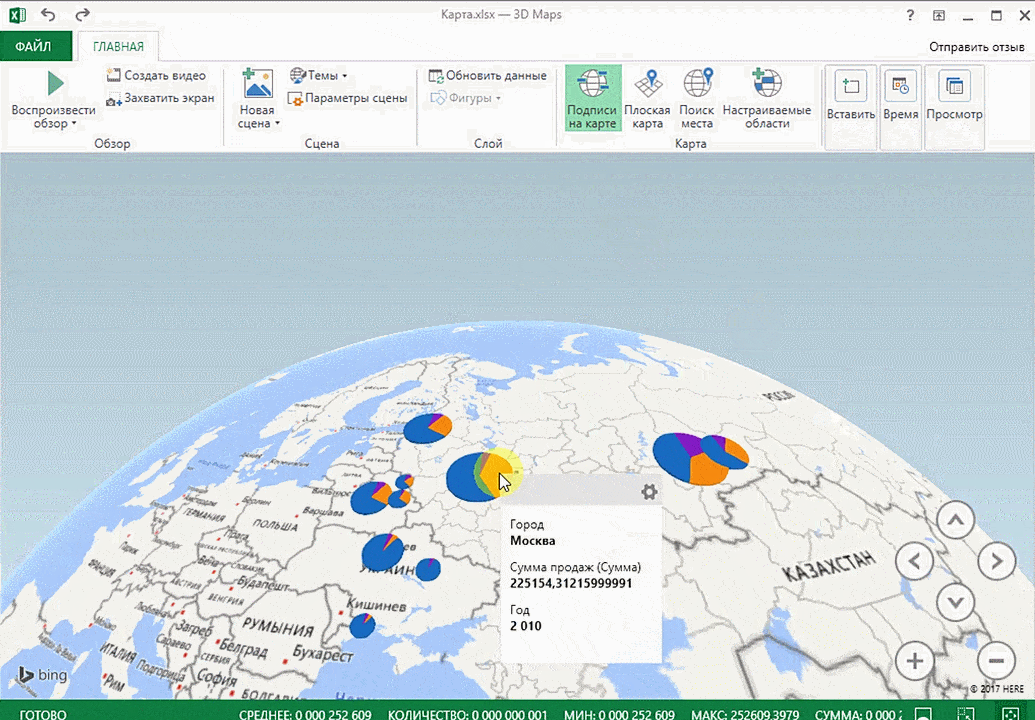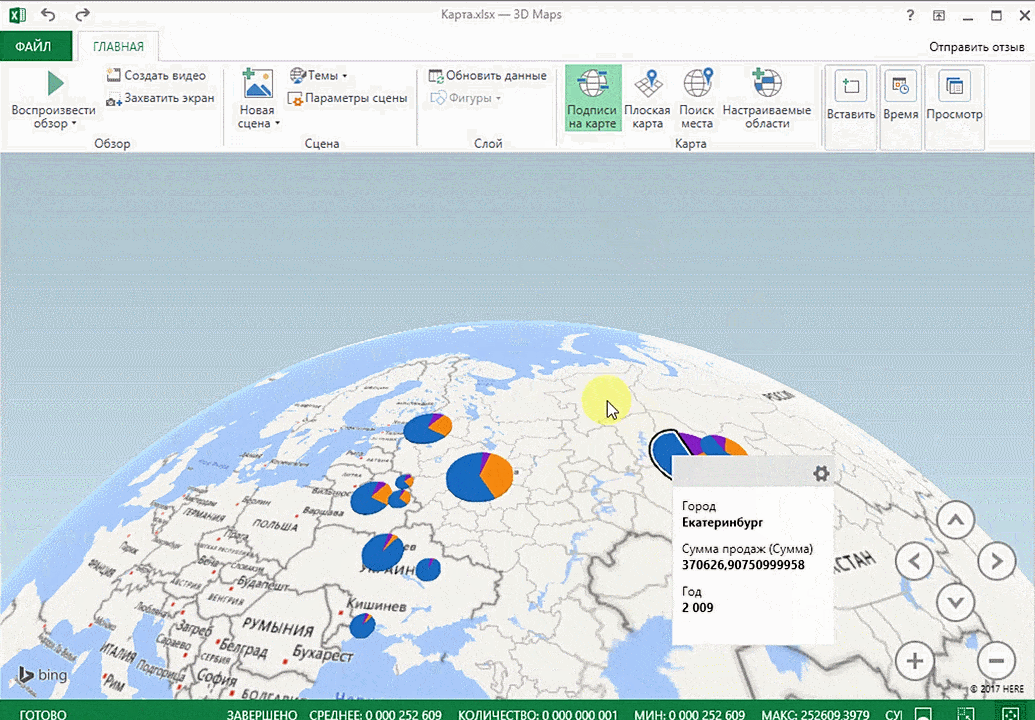
2. 3 D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение.
Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
- Откройте файл с таблицей, данные которой нужно визуализировать. Например, с информацией по разным городам и странам.
- Подготовьте данные для отображения на карте: «Главная» → «Форматировать как таблицу».
- Выделите диапазон данных для анализа.
- На вкладке «Вставка» есть кнопка 3D-карта.
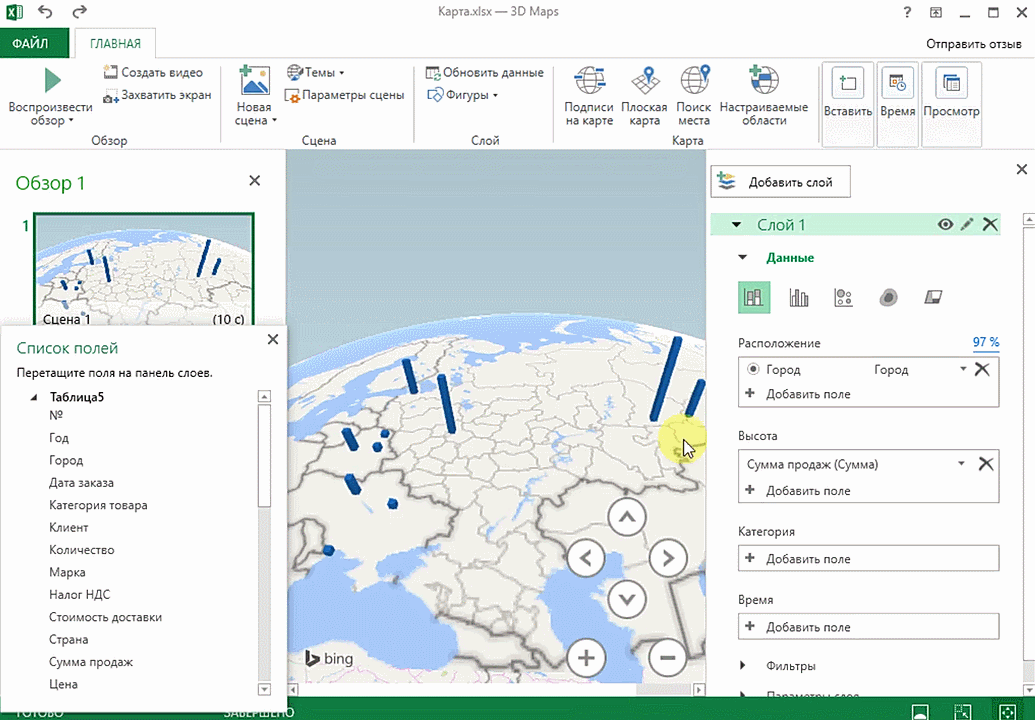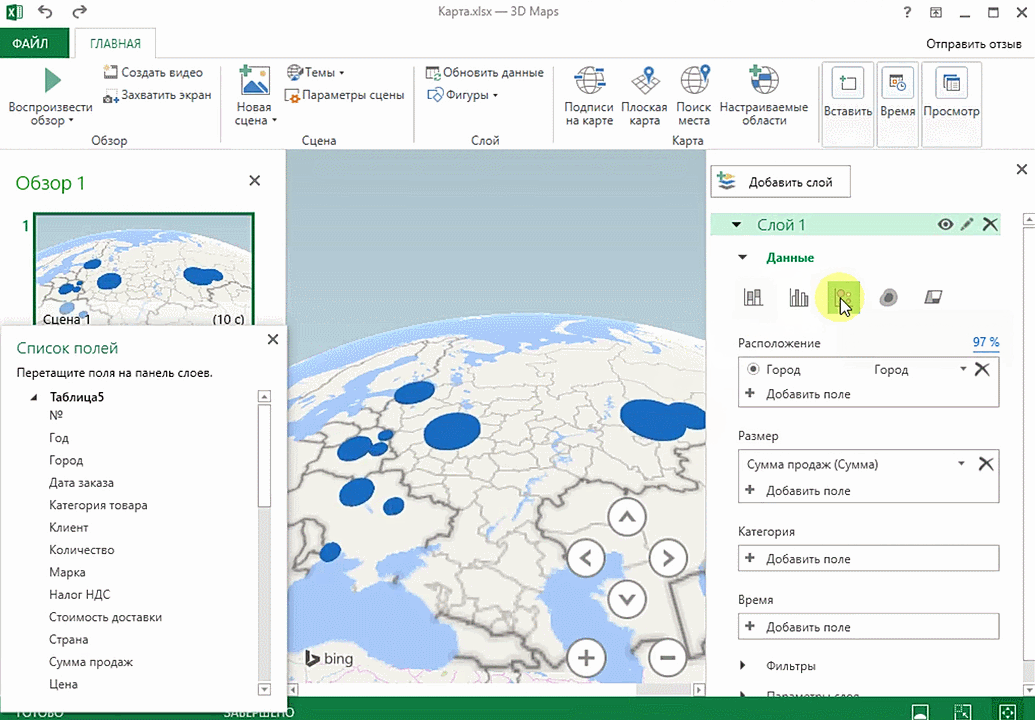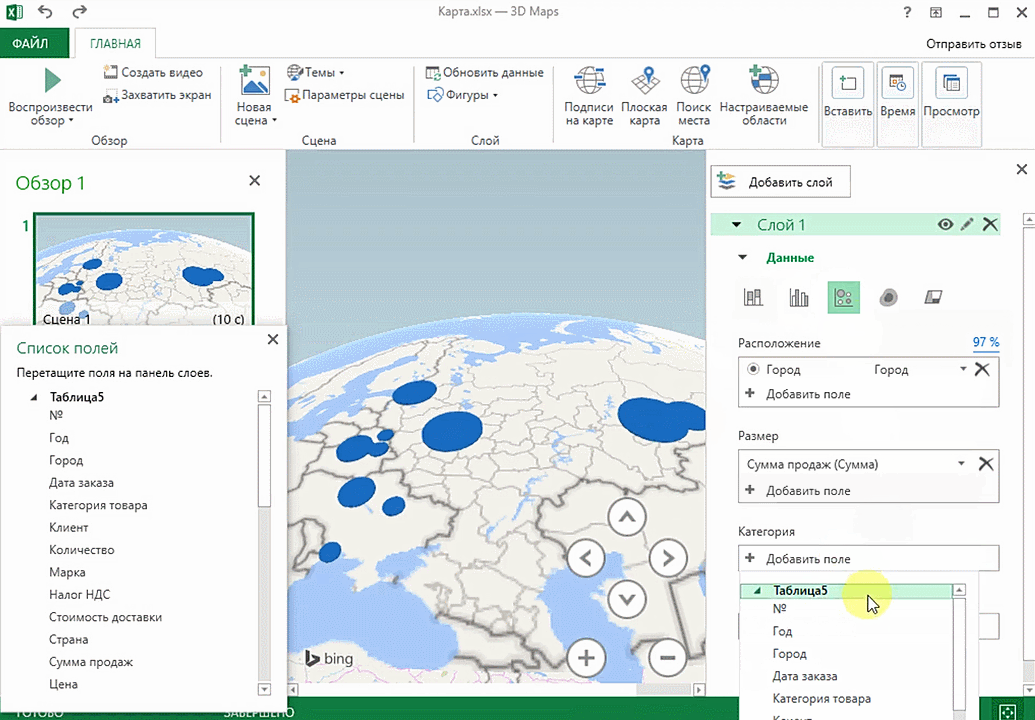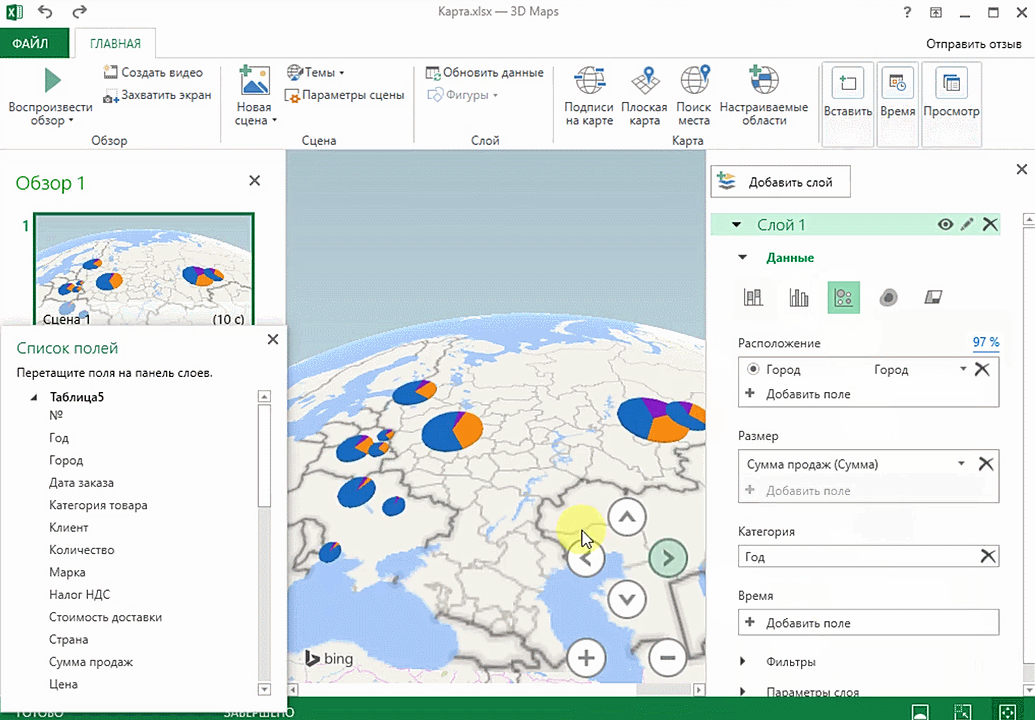
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение.
Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
- Откройте таблицу с данными за период и соответствующими ему показателями, например, от года.
- Выделите два ряда данных.
- На вкладке «Данные» в группе нажмите кнопку «Лист прогноза».
- В окне «Создание листа прогноза» выберите график или гистограмму для визуального представления прогноза.
- Выберите дату окончания прогноза.
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
На вкладке «Данные» в группе «Прогноз» нажимаем на «Лист прогноза». В появившемся окне «Создание листа прогноза» выбираем формат представления прогноза — график или гистограмму. В поле «Завершение прогноза» выбираем дату окончания, а затем нажимаем кнопку «Создать». Оранжевая линия — это и есть прогноз.
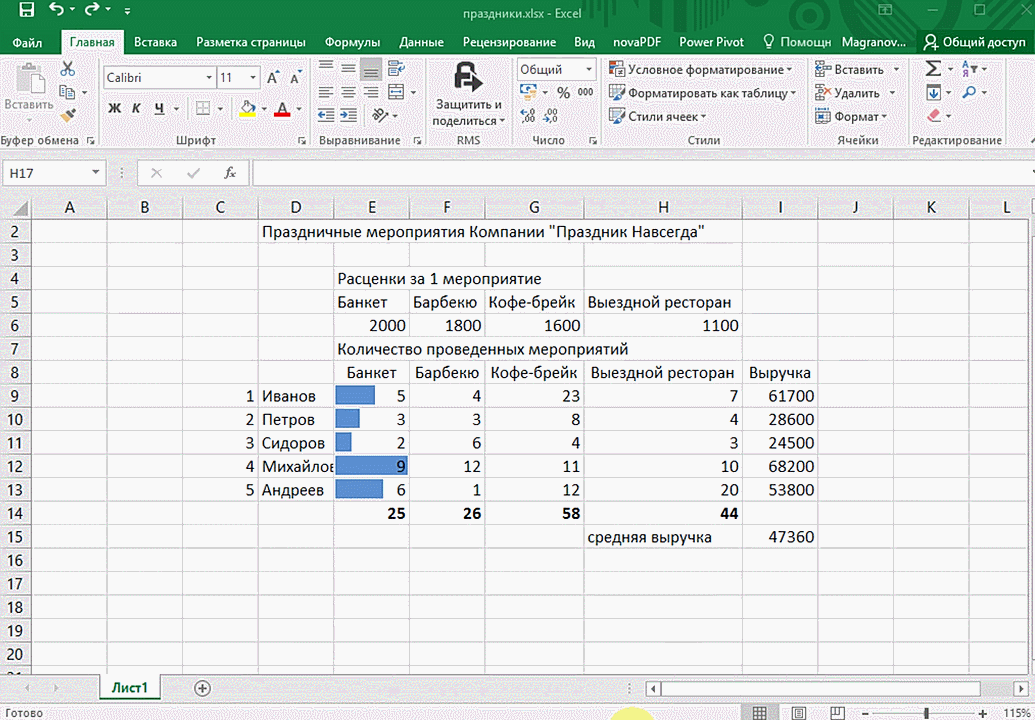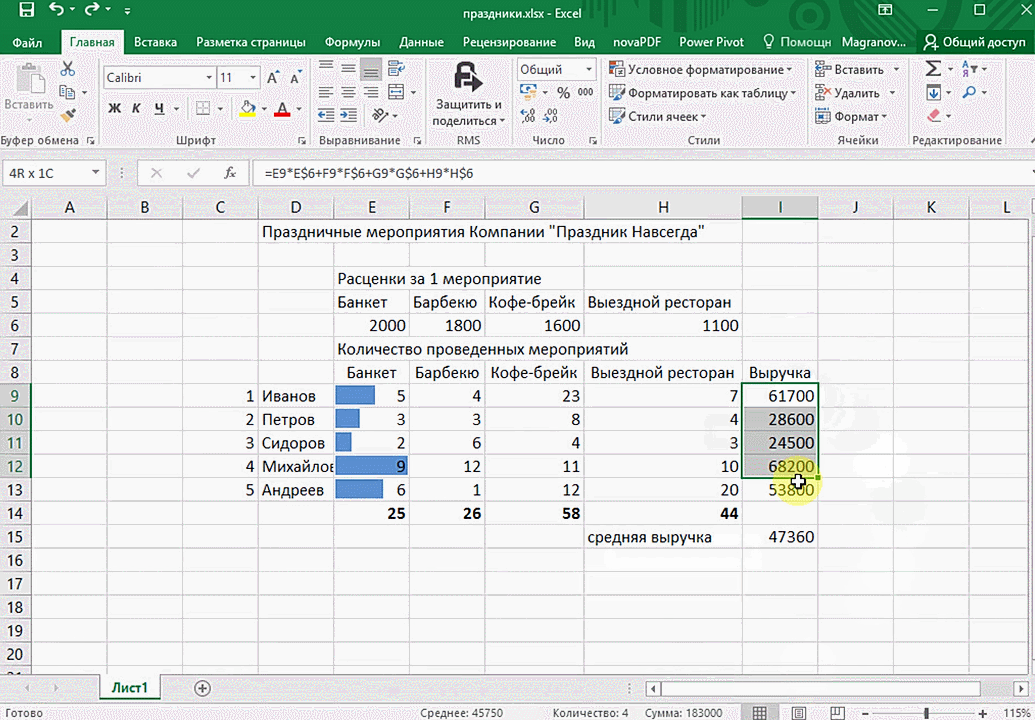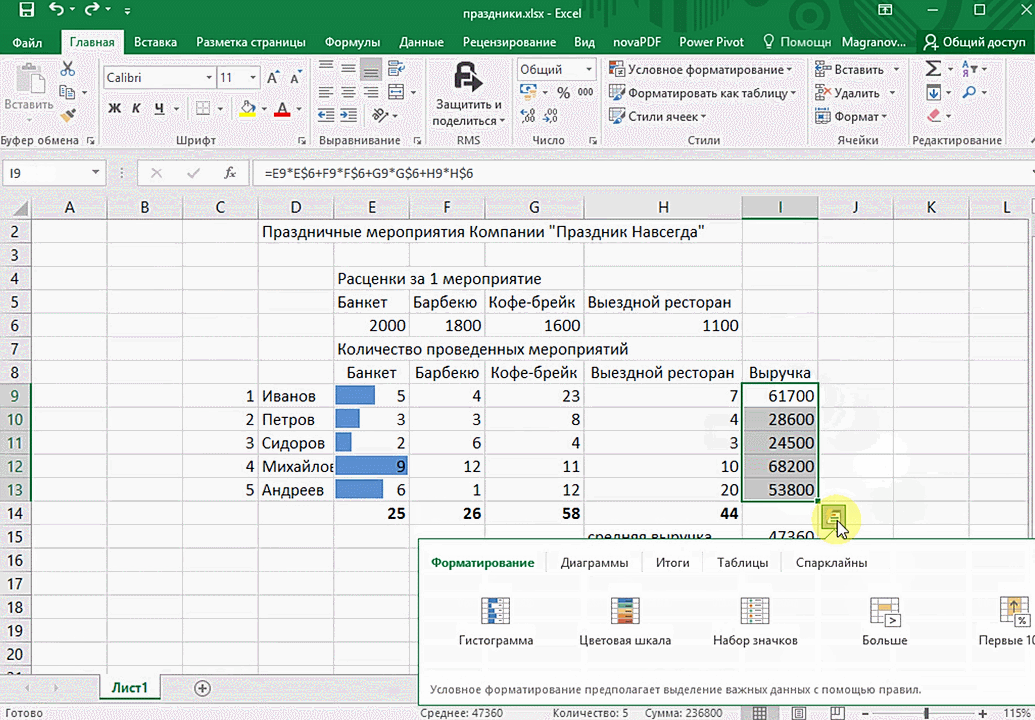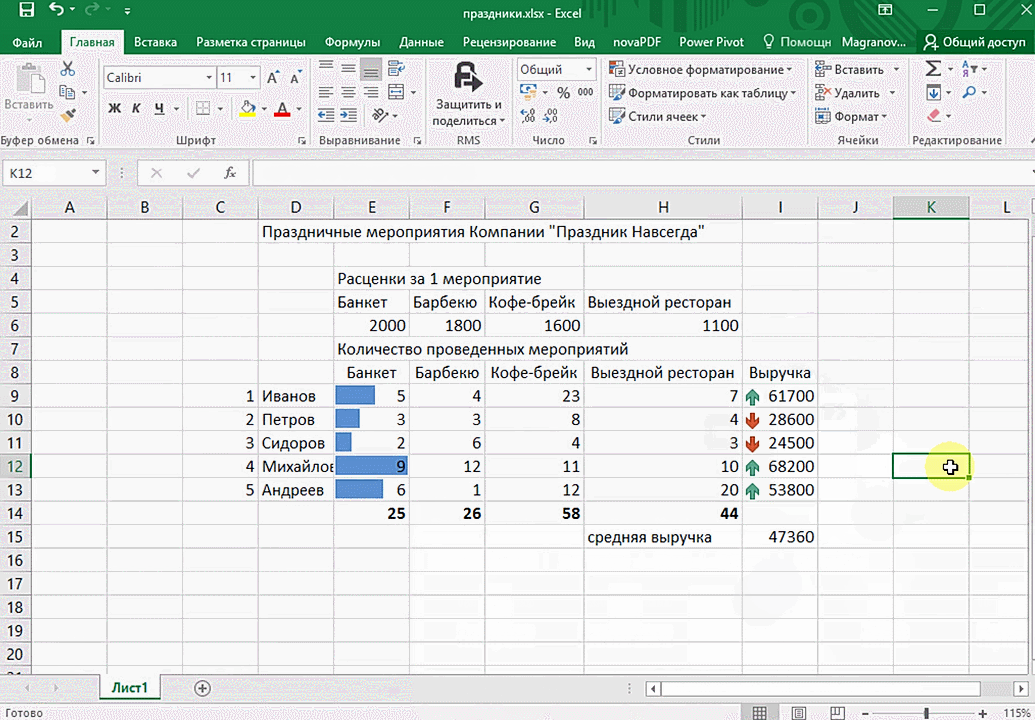
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение.
Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
- Откройте таблицу с данными для анализа.
- Выделите нужный для анализа диапазон.
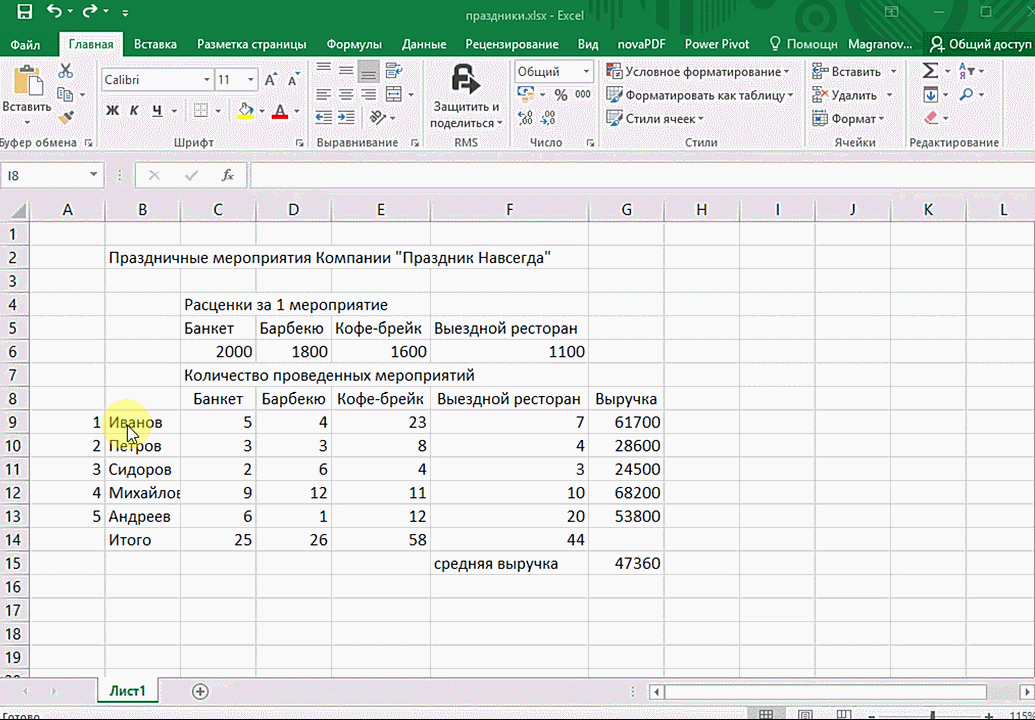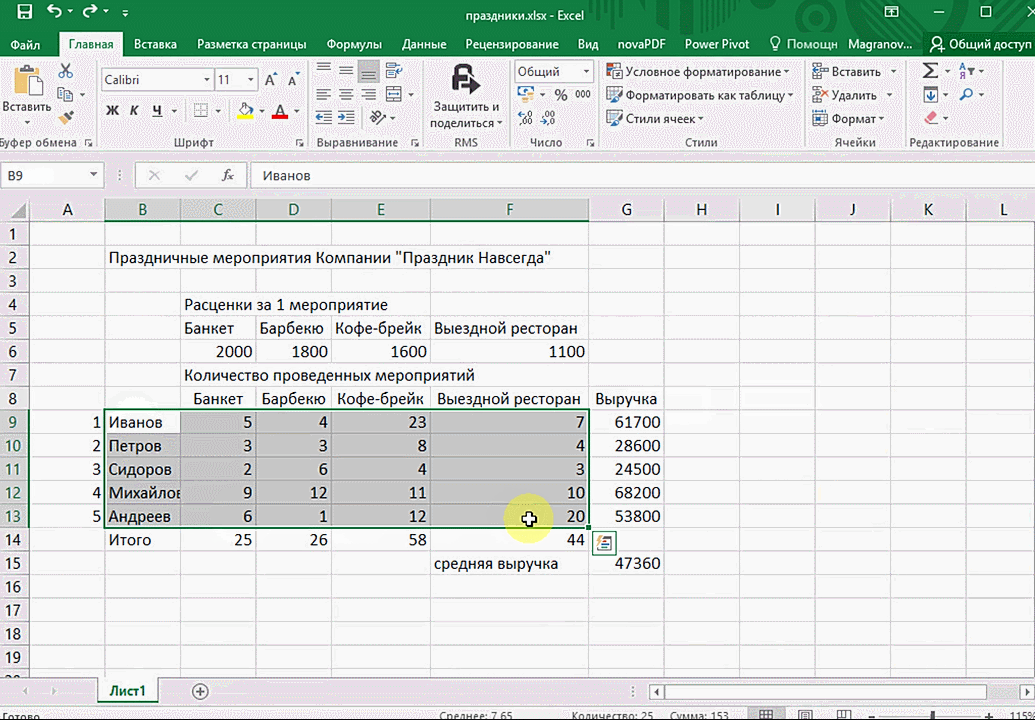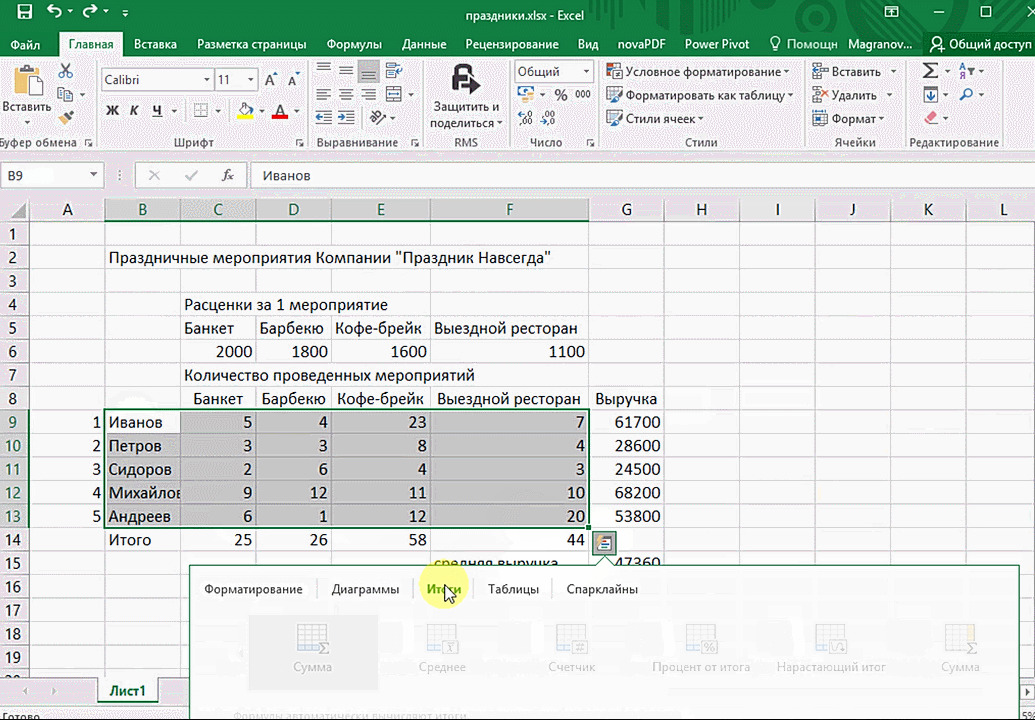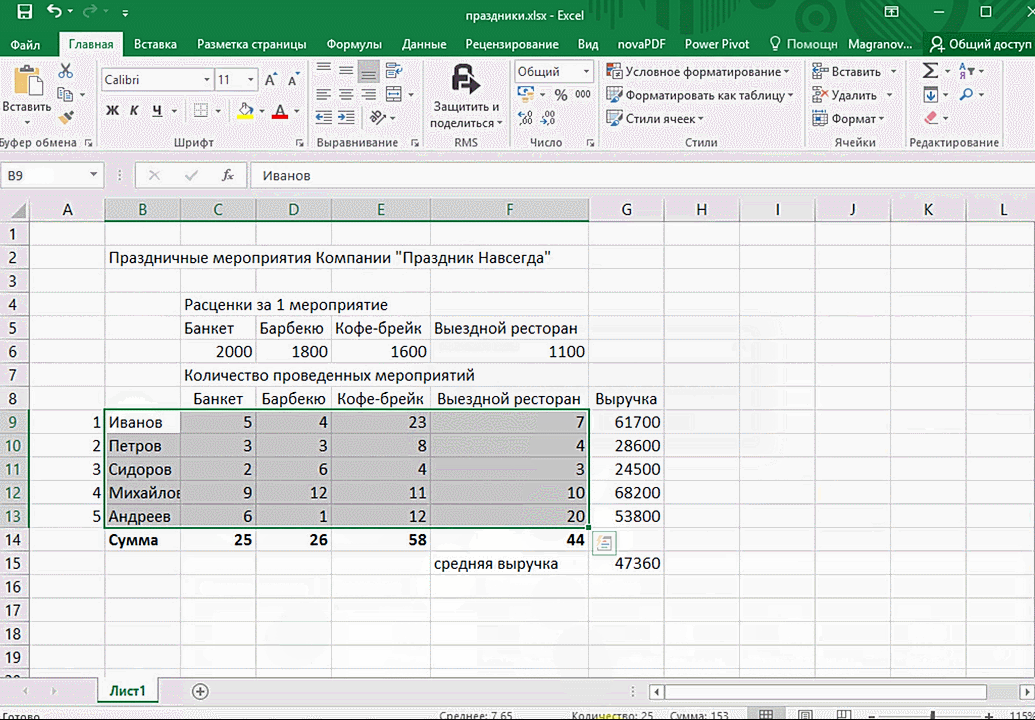
- При выделении диапазона внизу всегда появляется кнопка «Быстрый анализ». Она сразу предлагает совершить с данными несколько возможных действий. Например, найти итоги. Мы можем узнать суммы, они проставляются внизу.
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
Excel – одна из лучших программ для аналитика данных. А почти каждому человеку на том или ином этапе жизни приходилось иметь дело с цифрами и текстовыми данными и обрабатывать их в условиях жестких дедлайнов. Если вам и сейчас нужно это делать, то мы опишем техники, которые помогут существенно улучшить вам жизнь. А чтобы было более наглядно, покажем, как их воплощать, с помощью анимаций.
Анализ данных через сводные таблицы Excel
Сводные таблицы – один из самых простых способов автоматизировать обработку информации. Он позволяет свести в кучу огромный массив данных, которые абсолютно не структурированы. Если его использовать, можно почти навсегда забыть о том, что такое фильтр и ручная сортировка. А чтобы их создать, достаточно нажать буквально пару кнопок и внести несколько несложных параметров в зависимости от того, какой способ представления результатов нужен конкретно вам в определенной ситуации.
Пакет анализа данных, разработанный Майкрософт, можно использовать исключительно на едином листе в одну единицу времени. Если он будет обрабатывать информацию, расположенную на нескольких, то итоговая информация будет отображаться исключительно на одном. В других же будут показываться диапазоны без какой-либо значений, в которых есть исключительно форматы. Чтобы осуществить проанализировать информацию на нескольких листах, нужно использовать этот инструмент по отдельности. Это очень большой модуль, который поддерживает огромное количество возможностей, в частности, позволяет выполнять следующие типы обработки:
- Дисперсионный анализ.
- Корреляционный анализ.
- Ковариация.
- Вычисление скользящего среднего. Очень популярный метод в статистике и в трейдинге.
- Получать случайные числа.
- Выполнять операции с выборкой.
Эта надстройка не активирована по умолчанию, но входит в стандартный пакет. Чтобы ею воспользоваться, необходимо ее включить. Для этого сделайте следующие шаги:
- Перейдите в меню «Файл», и там найдите кнопку «Параметры». После этого перейдите в «Надстройки». Если же вы установили 2007 версию Эксель, то нужно нажать на кнопку «Параметры Excel», которая находится в меню Office.
- Далее появляется всплывающее меню, озаглавленное словом «Управление». Там находим пункт «Надстройки Excel», нажимаем на него, а потом – на кнопку «Перейти». Если же вы используете компьютер Apple, то достаточно открыть вкладку «Средства» в меню, а потом в раскрывающемся перечне найти пункт «Надстройки для Excel».
- В том диалоге, который появился после этого, нужно поставить галочку возле пункта «Пакет анализа», после чего подтвердить свои действия, нажав кнопку «ОК».
В некоторых ситуациях может оказаться так, что этого дополнения найти не удалось. В этом случае его не будет в перечне аддонов. Для этого надо нажать на кнопку «Обзор». Может также появиться информация о том, что пакет полностью отсутствует на этом компьютере. В этом случае необходимо его установить. Для этого нужно нажать на кнопку «Да».
Перед тем, как включить пакет анализа, необходимо сначала активировать VBA. Для этого его нужно загрузить таким же способом, как и саму надстройку.
Как работать со сводными таблицами
Первоначальная информация может быть какой-угодно. Это могут быть сведения о продажах, доставке, отгрузках продукции и так далее. Независимо от этого, последовательность шагов будет всегда одинаковой:
- Откройте файл, в котором содержится таблица.
- Выделите диапазон ячеек, которые мы будем анализировать с помощью сводной таблицы.
- Откройте вкладку «Вставка, и там надо найти группу «Таблицы», где есть кнопка «Сводная таблица». Если же используется компьютер под операционной системой Mac OS, то нужно открыть вкладку «Данные», и эта кнопка будет находиться во вкладке «Анализ».
- После этого откроется диалог с заголовком «Создание сводной таблицы».
- Затем выставите такое отображение данных, которое соответствует выделенному диапазону.
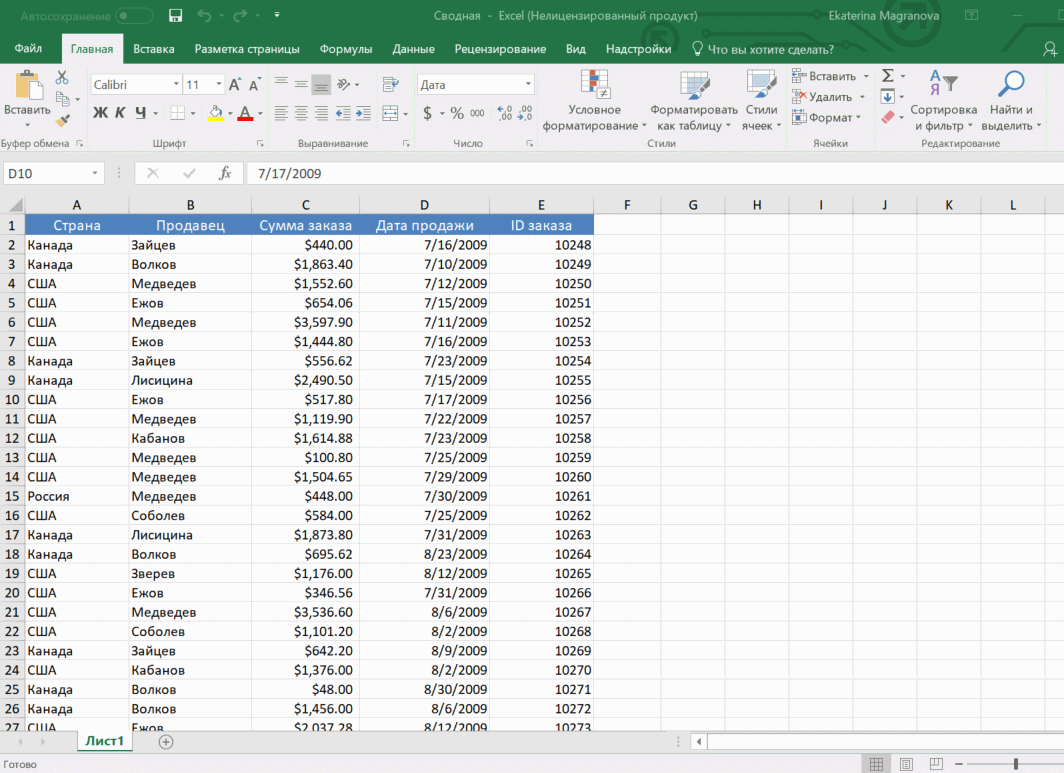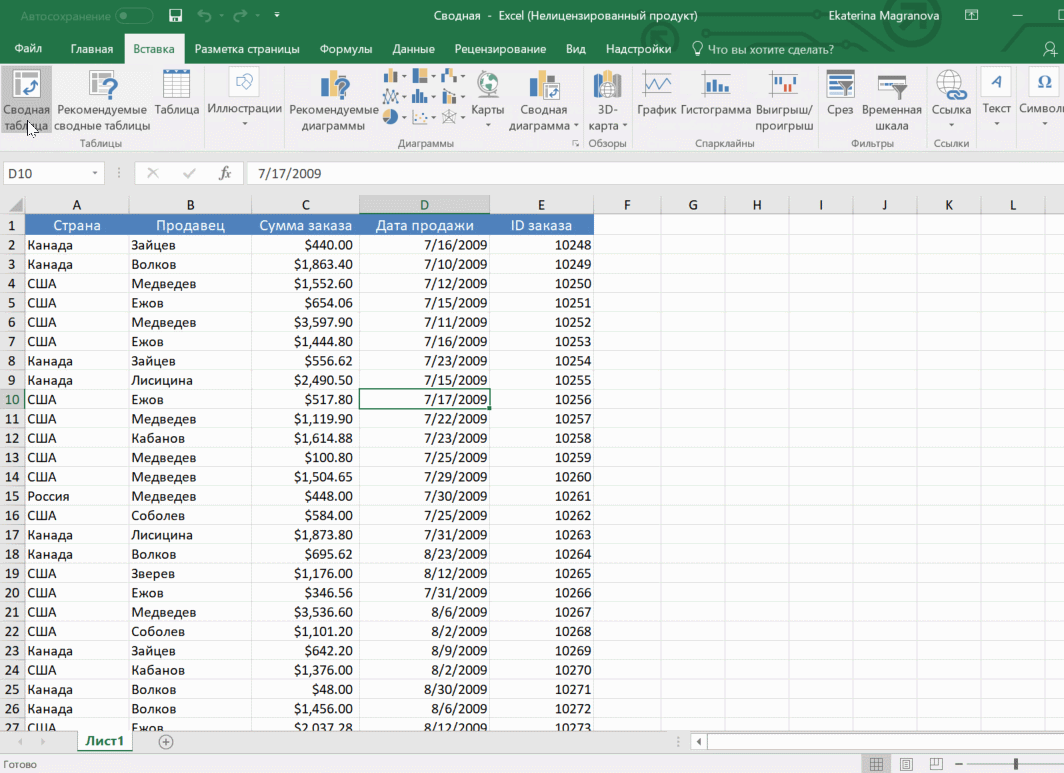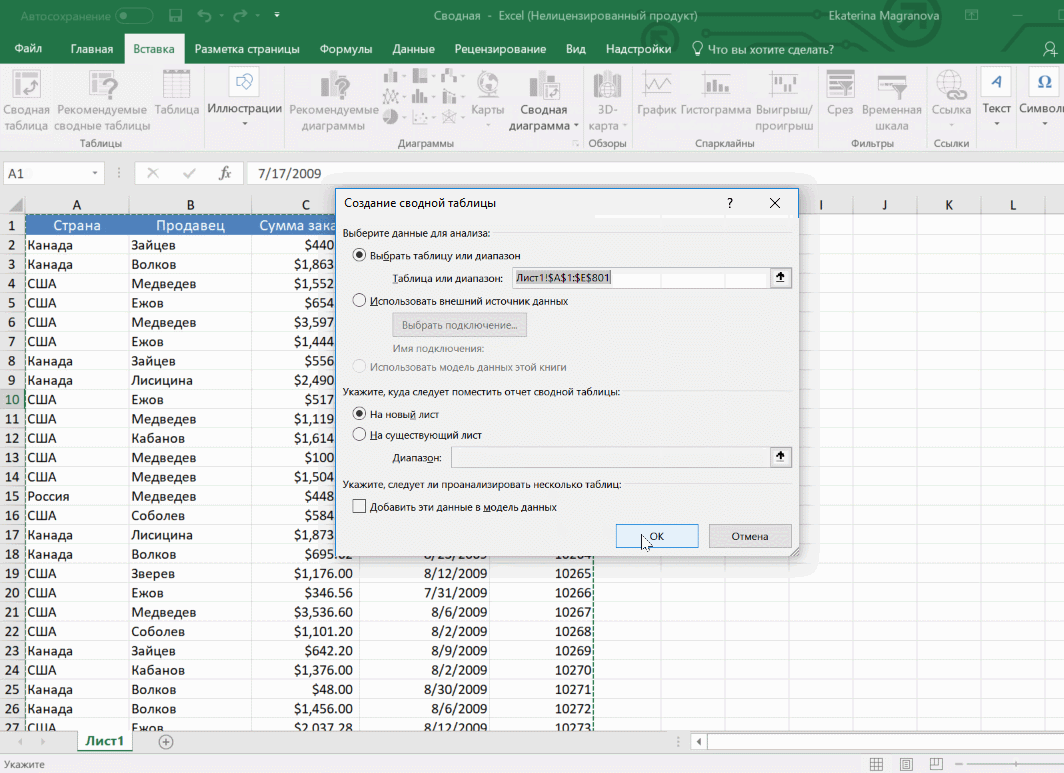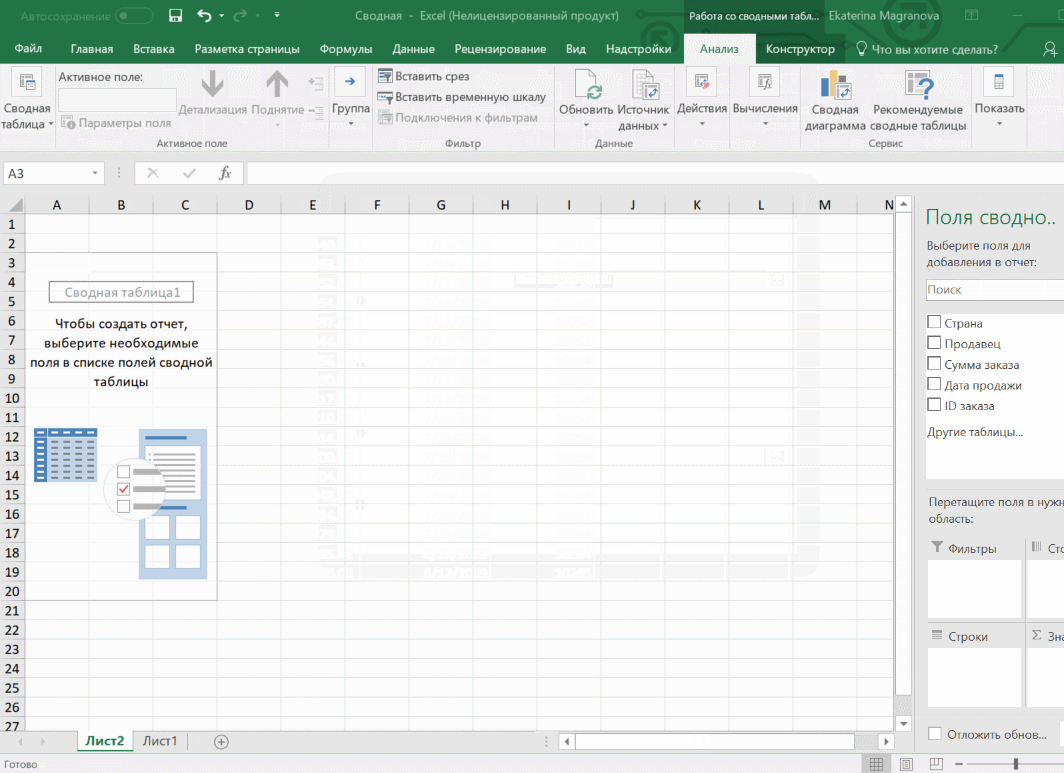
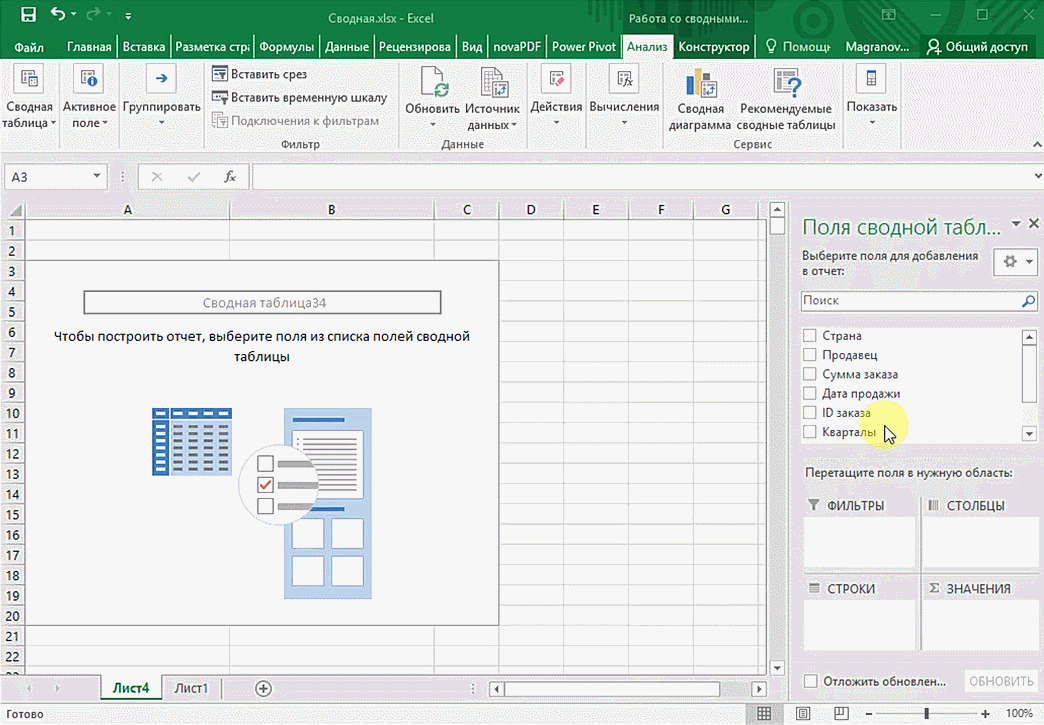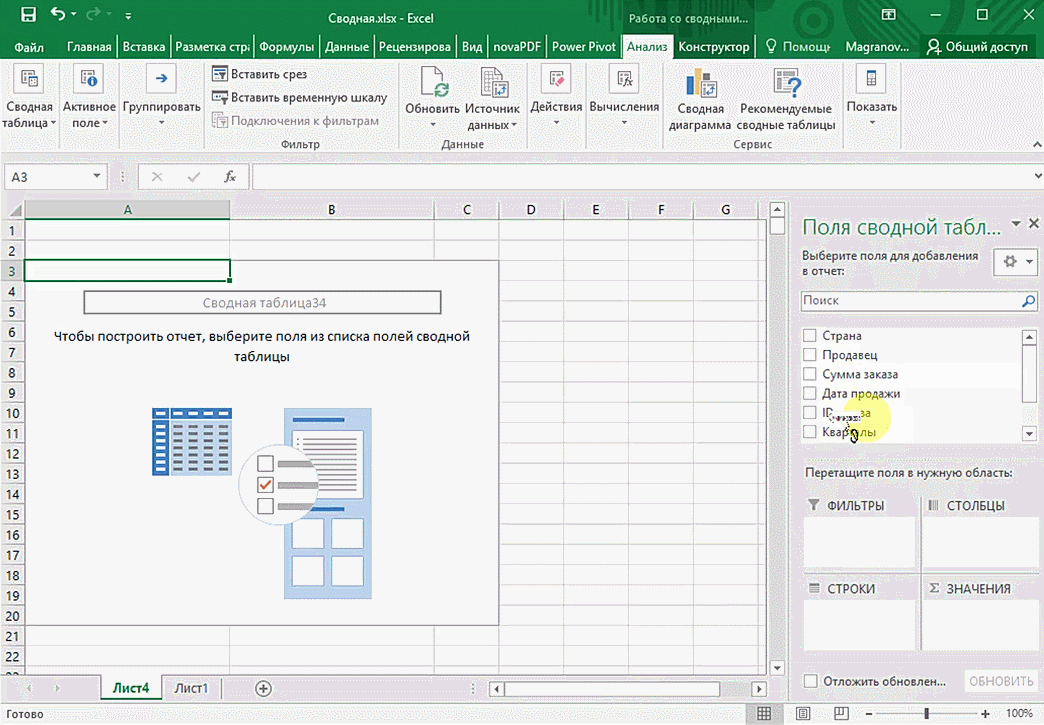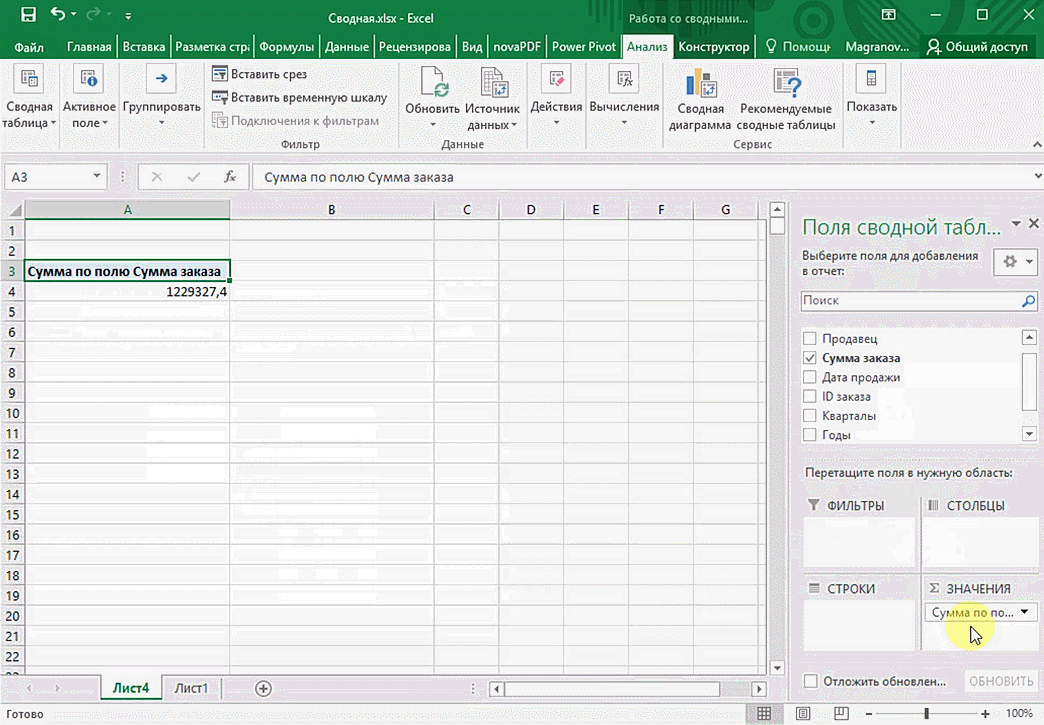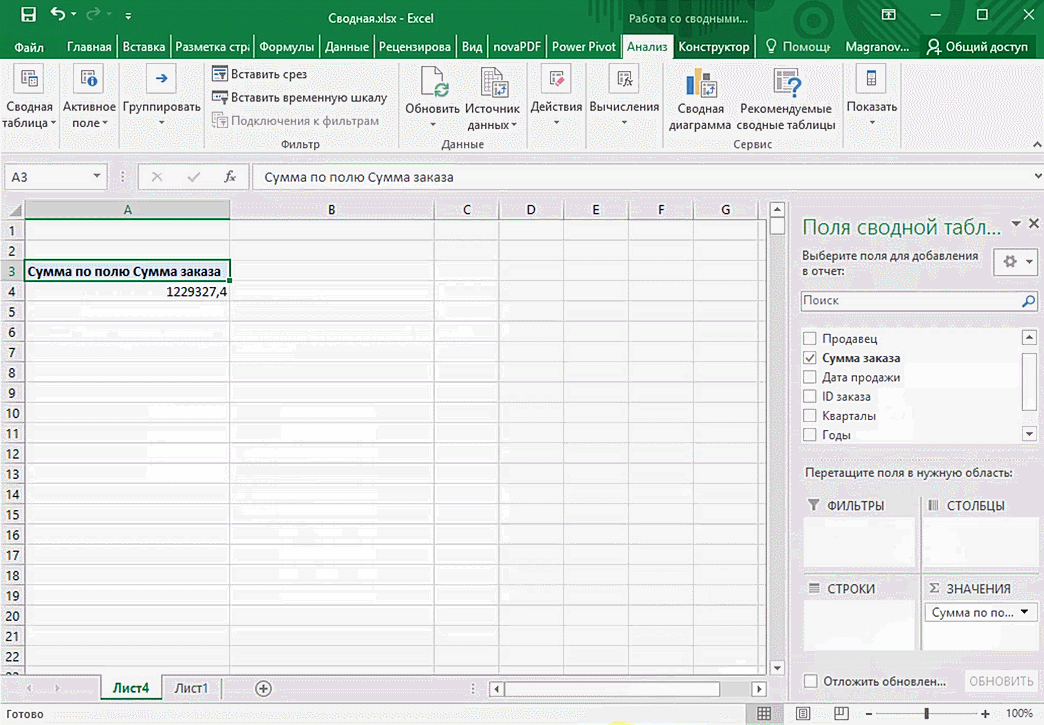
Мы открыли таблицу, информация в которой никоим образом не структурирована. Чтобы это сделать, можно воспользоваться настройками полей сводной таблицы в правой стороне экрана. Например, отправим в поле «Значения» «Сумму заказов», а информацию про продавцов и дату продажи – в строки таблицы. Исходя из данных, которые содержатся в этой таблице, автоматически определились суммы. Если есть необходимость, можно открыть информацию по каждому году, кварталу или месяцу. Это позволит получить детальную информацию, которая надо в конкретный момент.
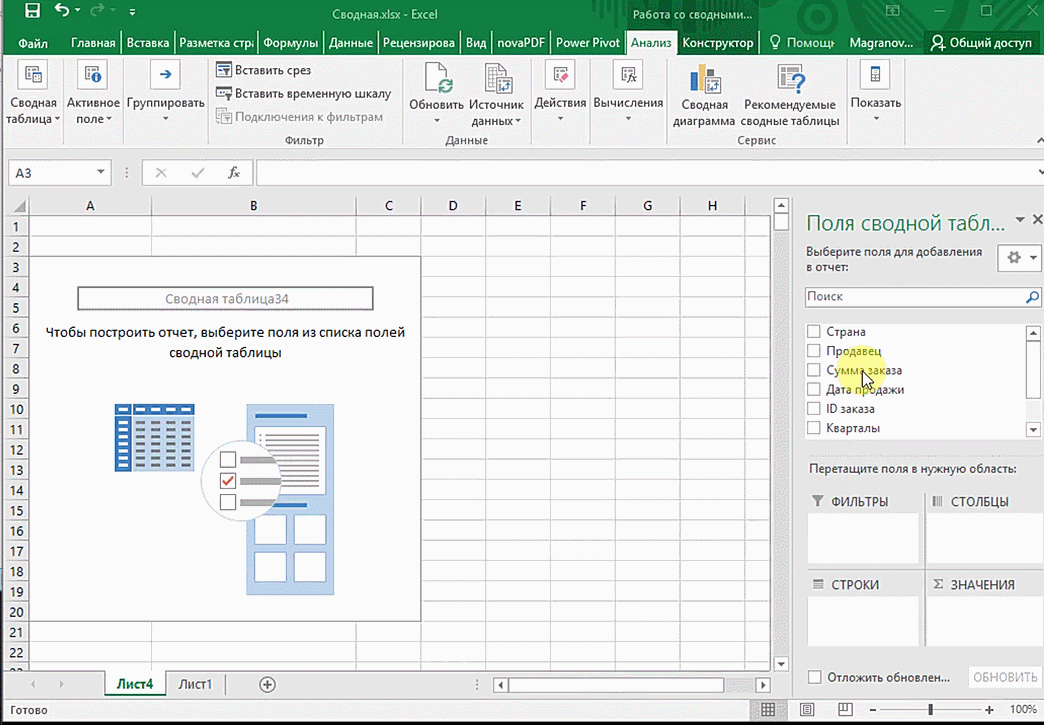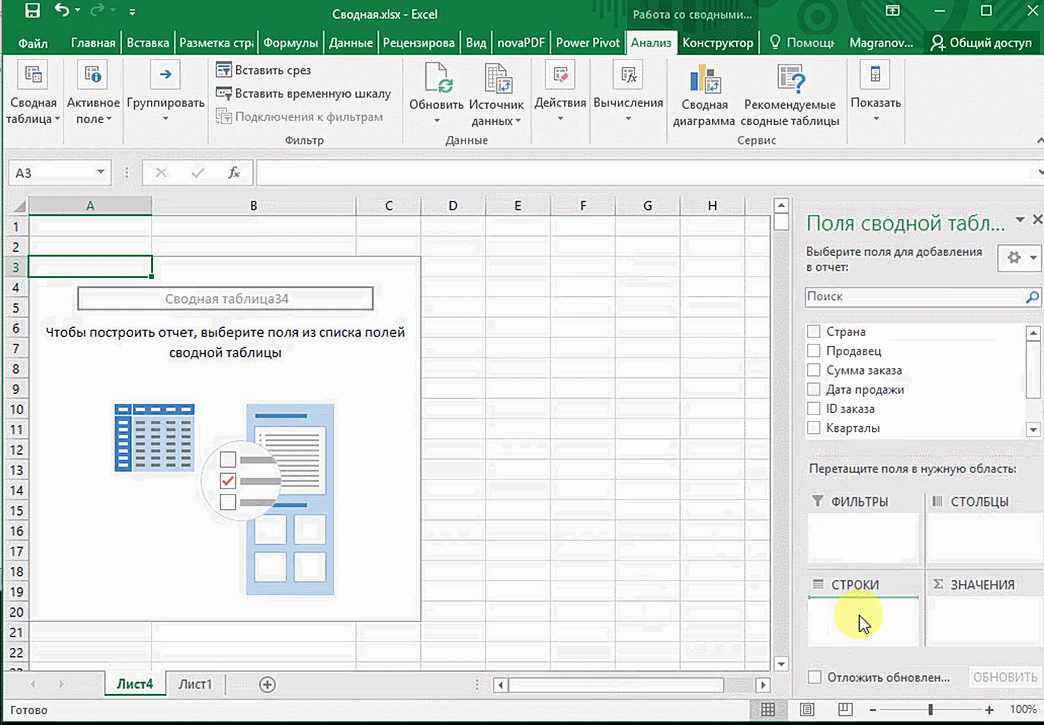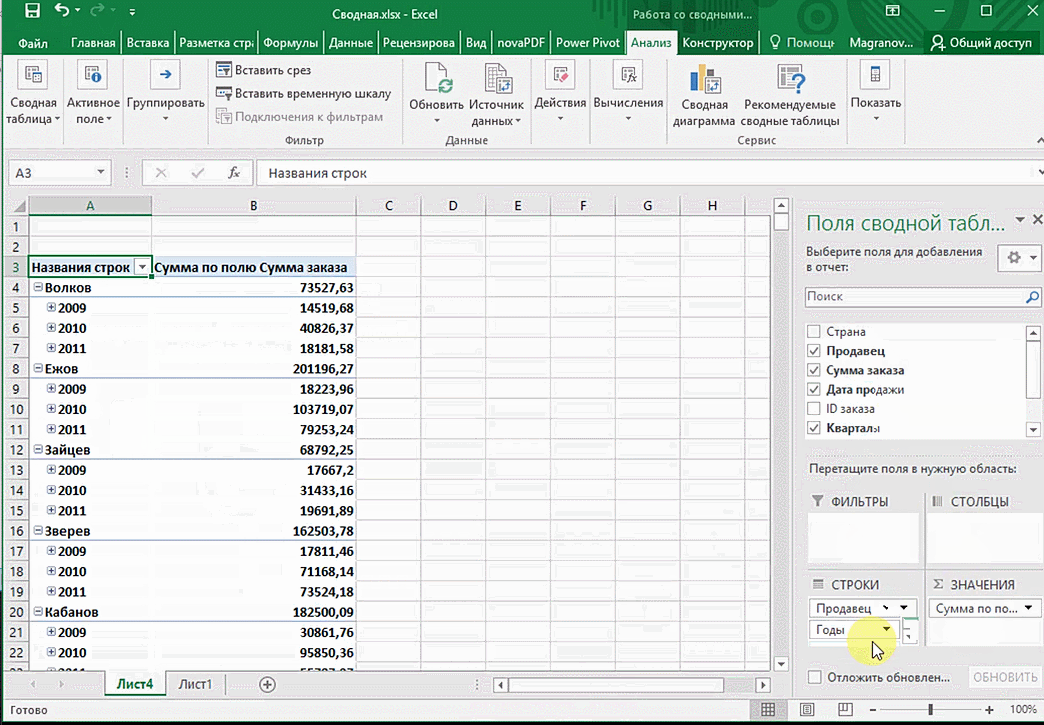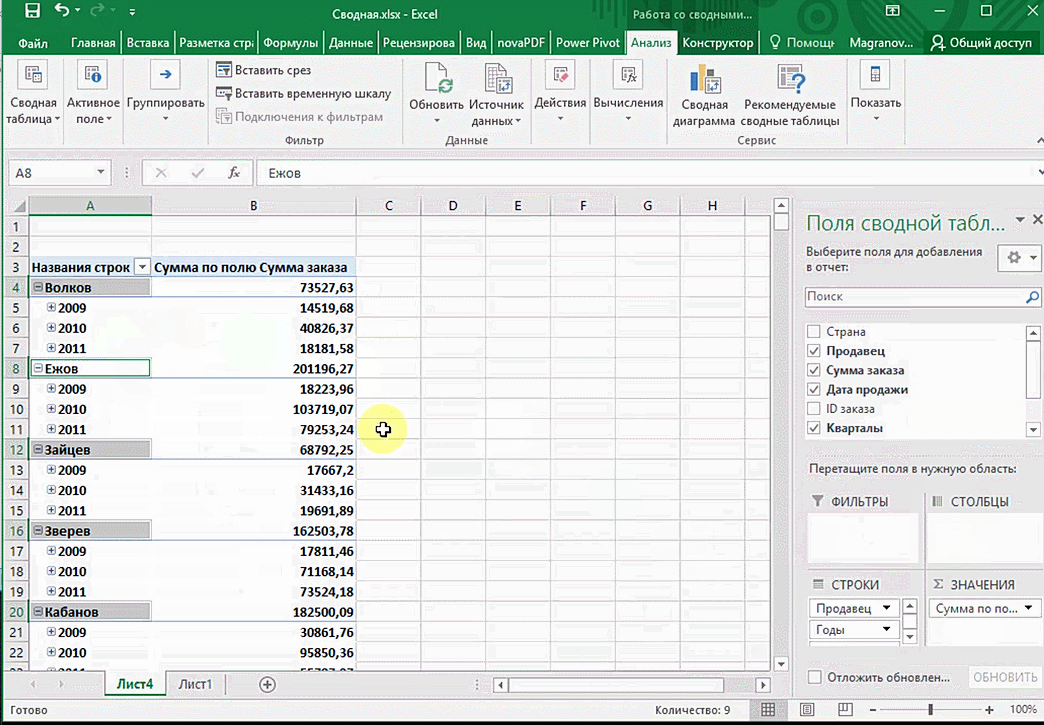
От того, сколько колонок есть, будет отличаться и набор имеющихся параметров. Например, общее число столбцов – 5. И нам надо просто разместить и выбрать их верным образом, а показать сумму. В таком случае выполняем действия, показанные на этой анимации.
Можно сводную таблицу конкретизировать, указав, например, страну. Для этого мы включаем пункт «Страна».
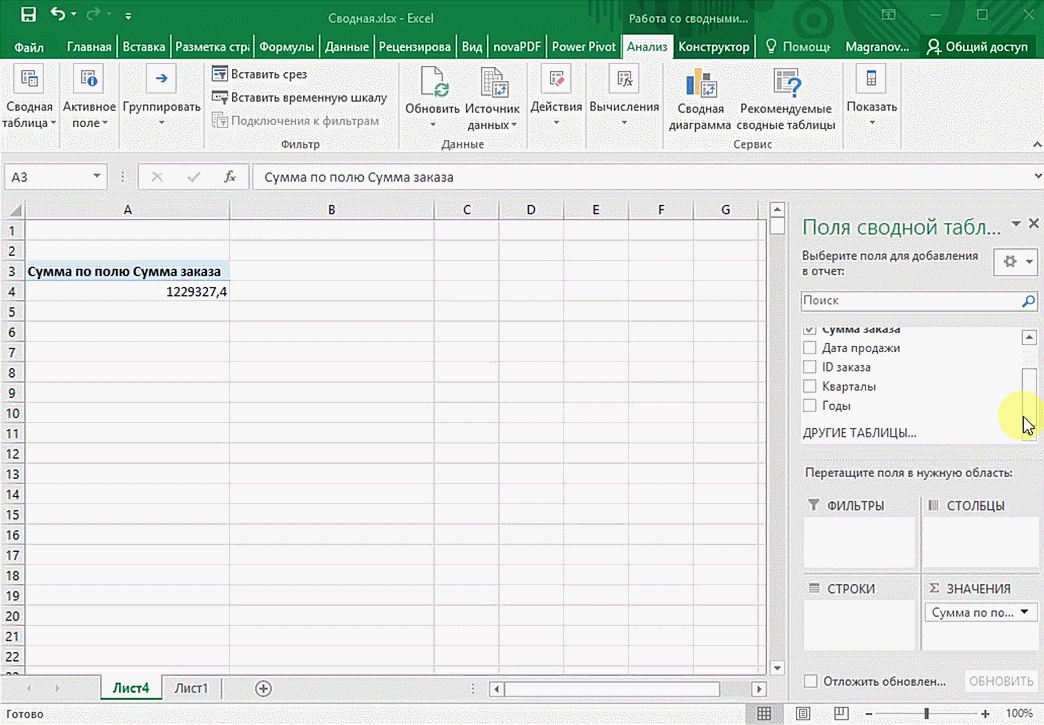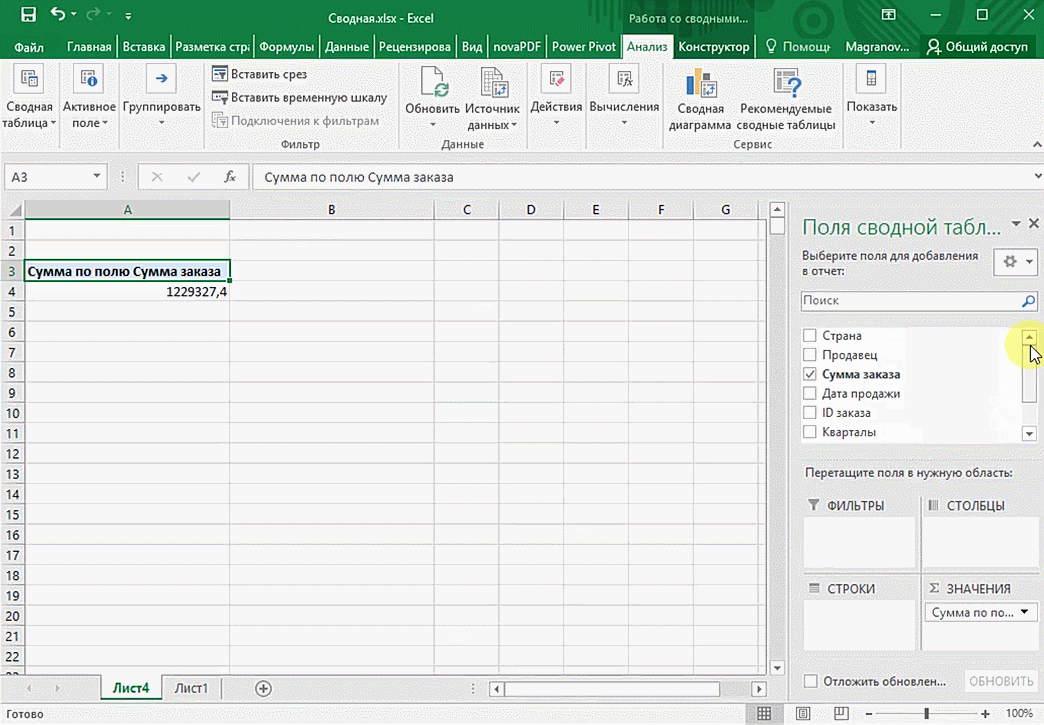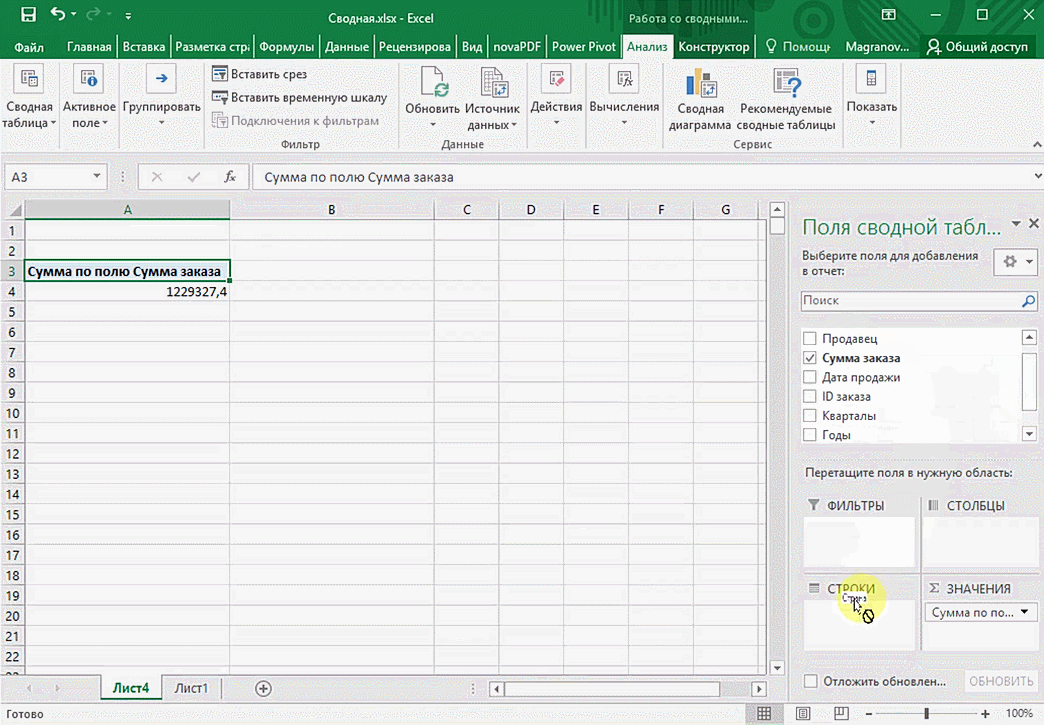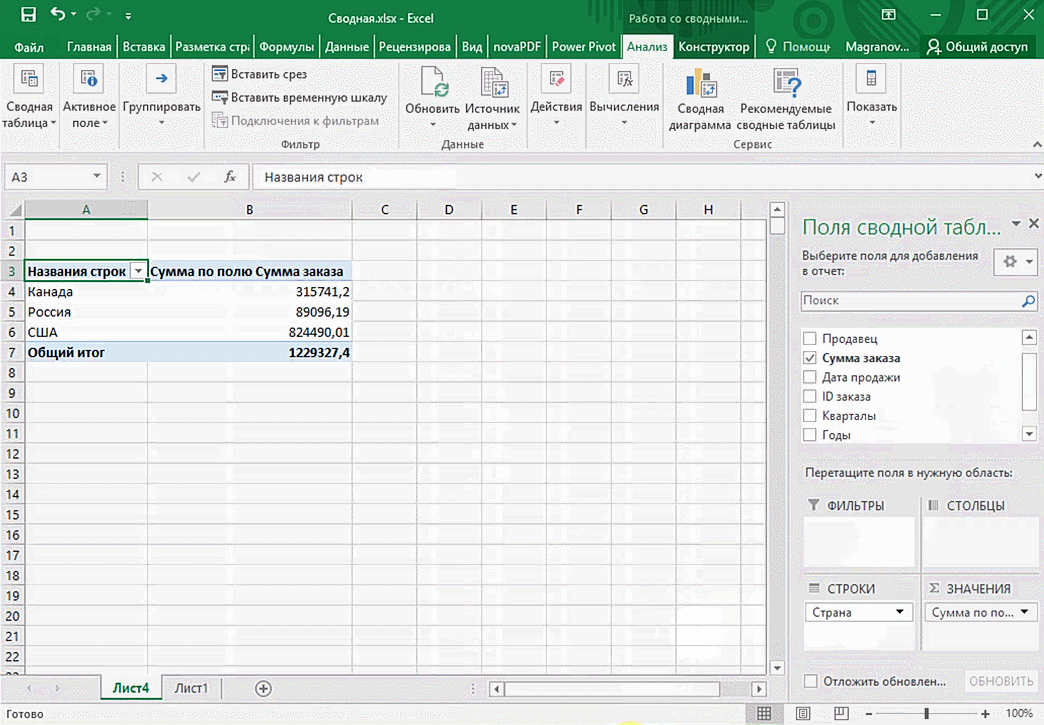
Можно также посмотреть информацию про продавцов. Для этого мы заменяем колонку «Страна» на «Продавец». Результат получится следующий.
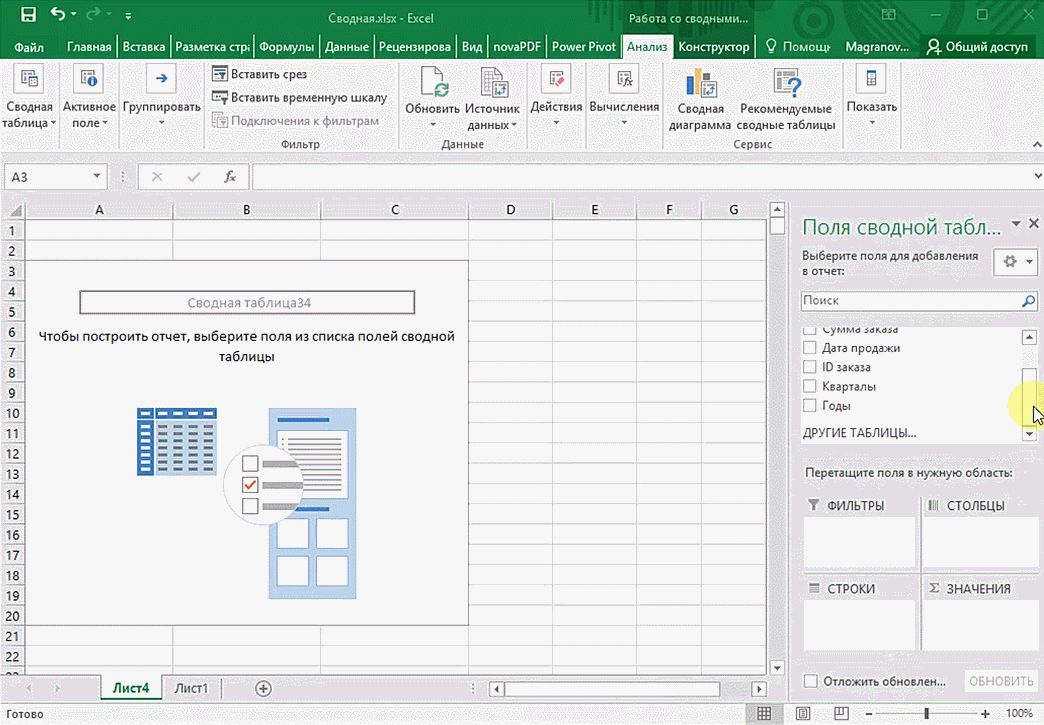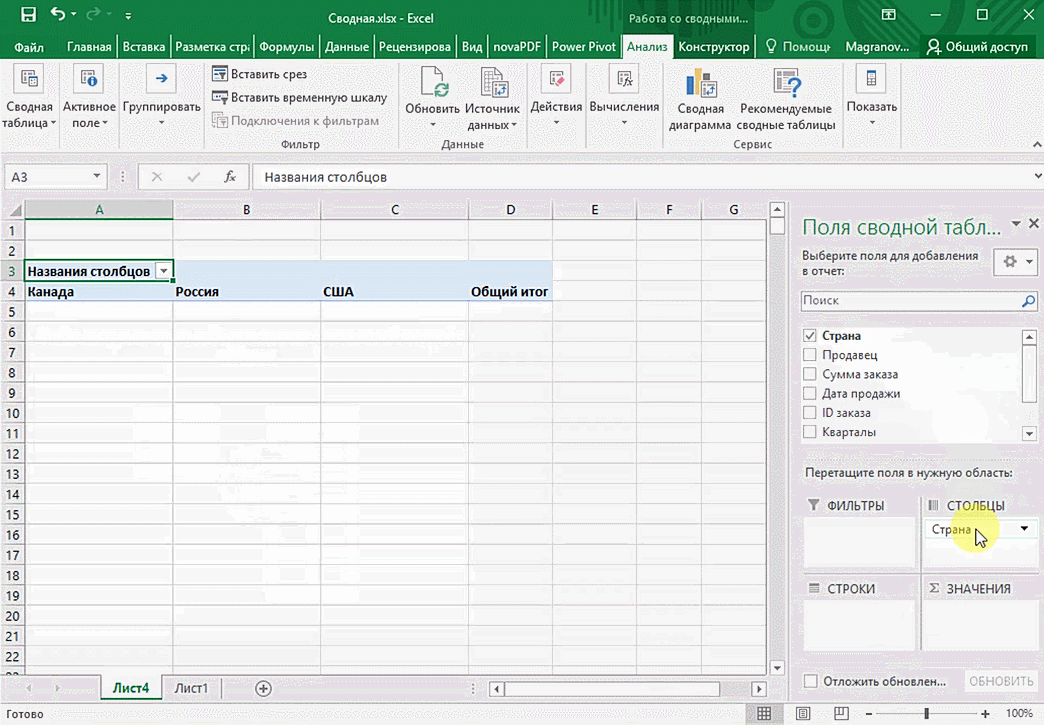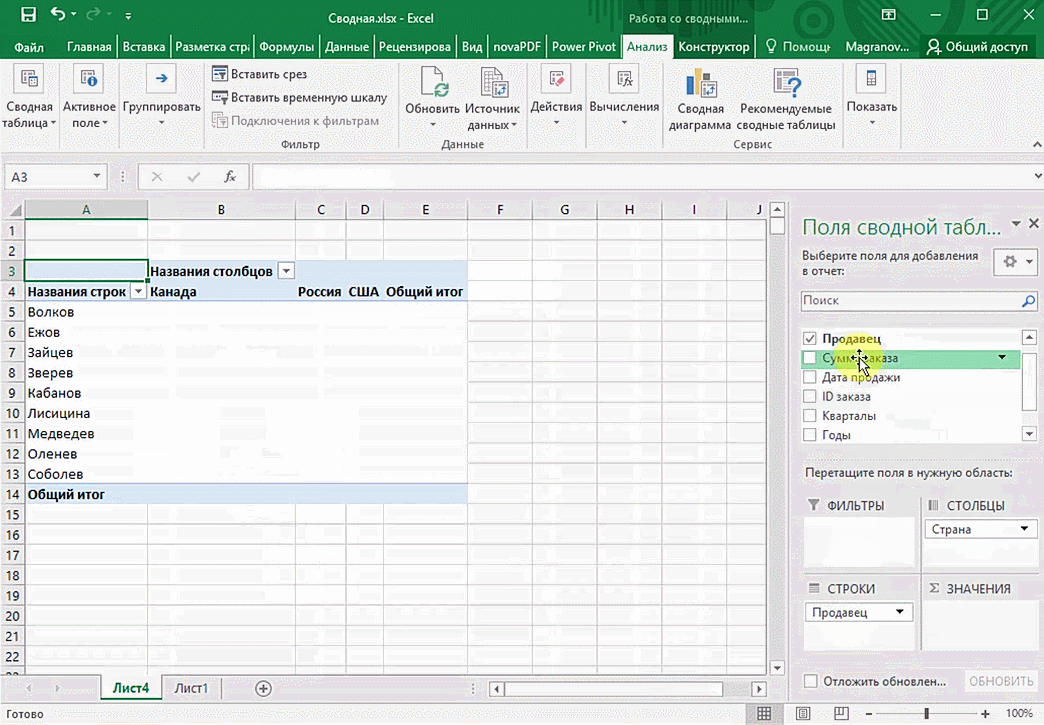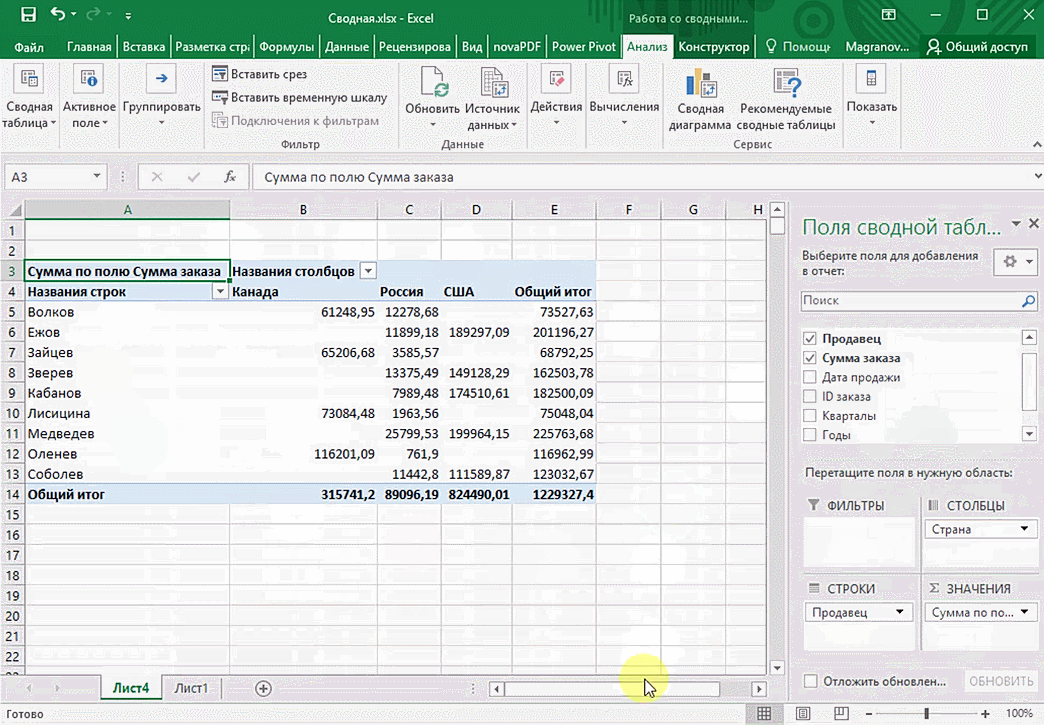
Анализ данных с помощью 3D-карт
Данный метод визуального представления с географической привязкой дает возможность искать закономерности, привязанные к регионам, а также анализировать информацию этого типа.
Преимущество этого способа в том, что нет необходимости отдельно прописывать координаты. Необходимо просто правильно написать географическое положение в таблице.
Как работать с 3D-картами в Excel
Последовательность действий, которую вам необходимо выполнить, чтобы работать с 3Д-картами, следующая:
- Откройте файл, в котором есть интересующий диапазон данных. Например, таблица, где есть колонка «Страна» или «Город».
- Информацию, которая будет показываться на карте, нужно сначала отформатировать, как таблицу. Для этого надо найти соответствующий пункт на вкладке «Главная».
- Выделите те ячейки, которые будут анализироваться.
- После этого переходим на вкладку «Вставка», и там находим кнопку «3Д-карта».
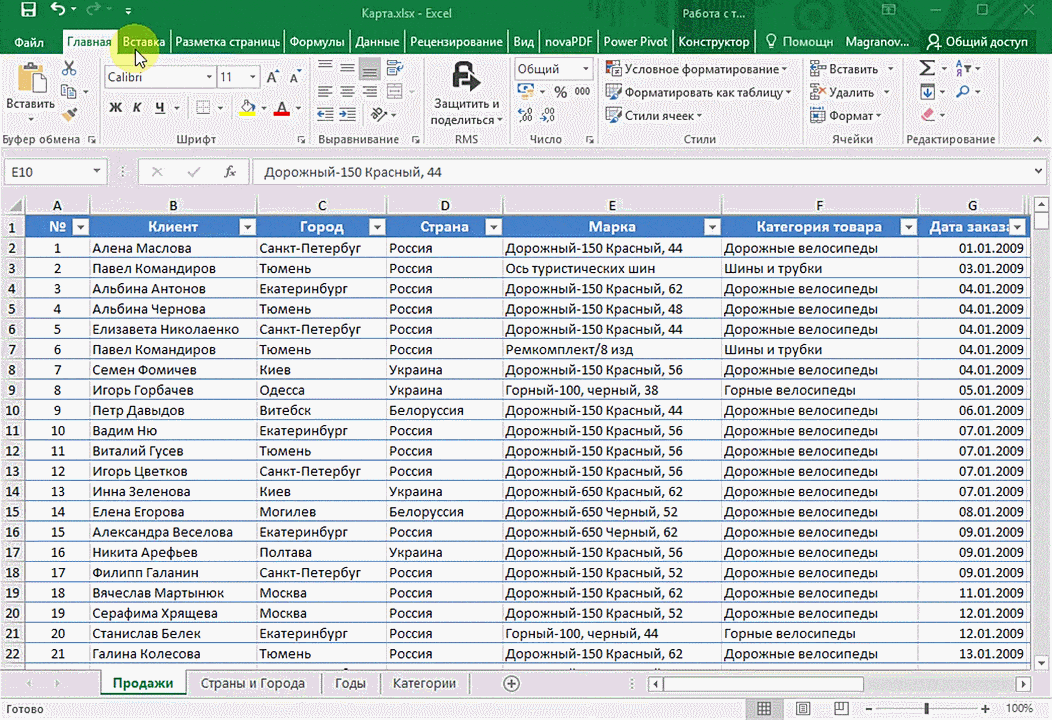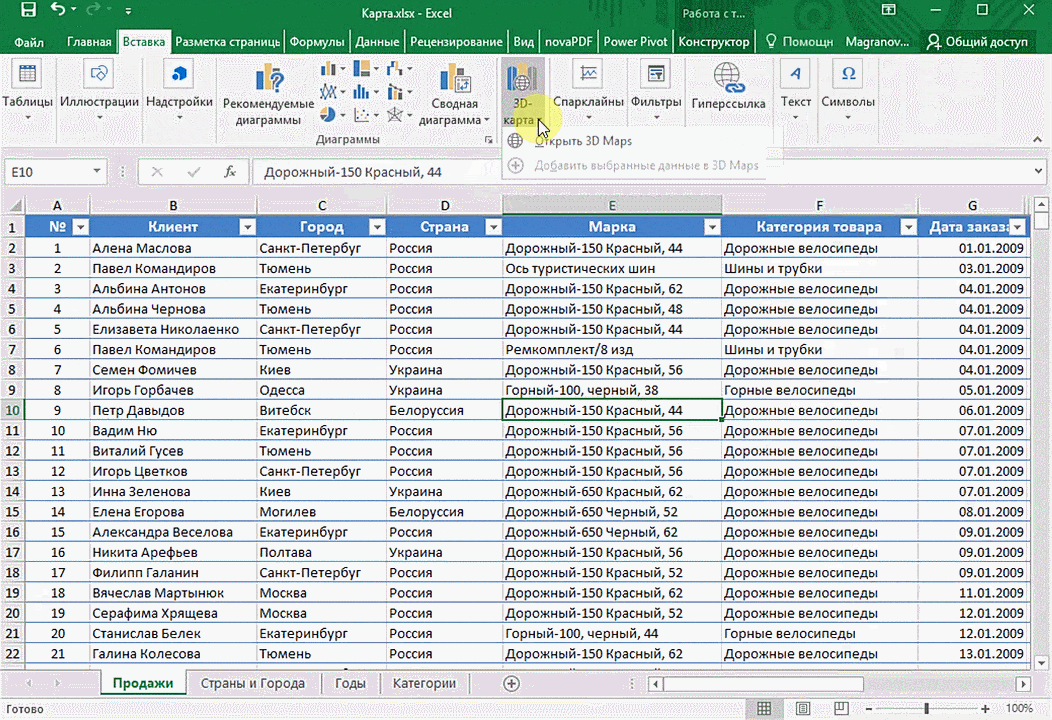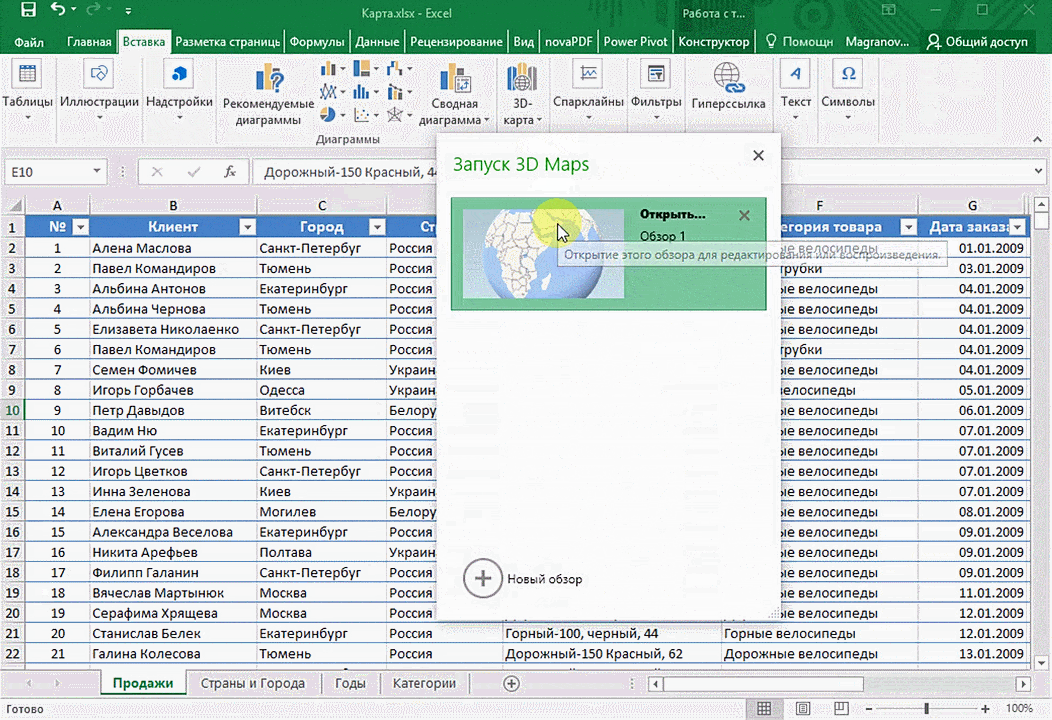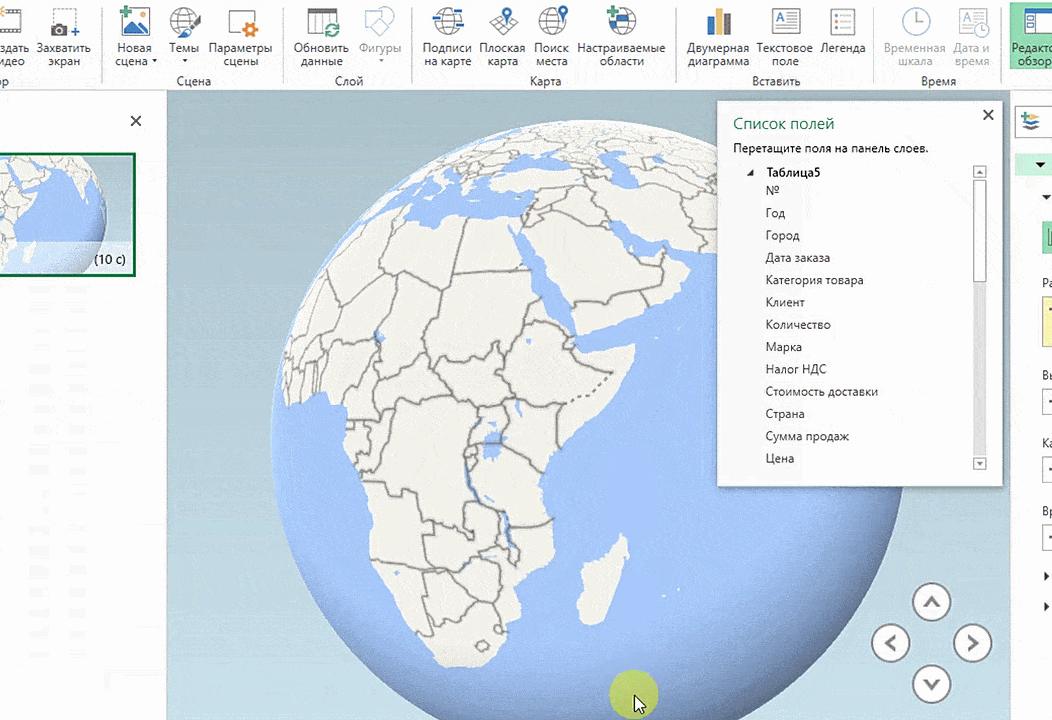
Затем показывается наша карта, где города в таблице представлены в виде точек. Но нам не особо нужно просто наличие информации о населенных пунктах на карте. Нам гораздо важнее видеть ту информацию, которая привязана к ним. Например, те суммы, которые можно показать, как высоту столбика. После того, как мы выполним действия, указанные на этой анимации, при наведении курсора на соответствующий столбик будут отображаться привязанные к нему данные.
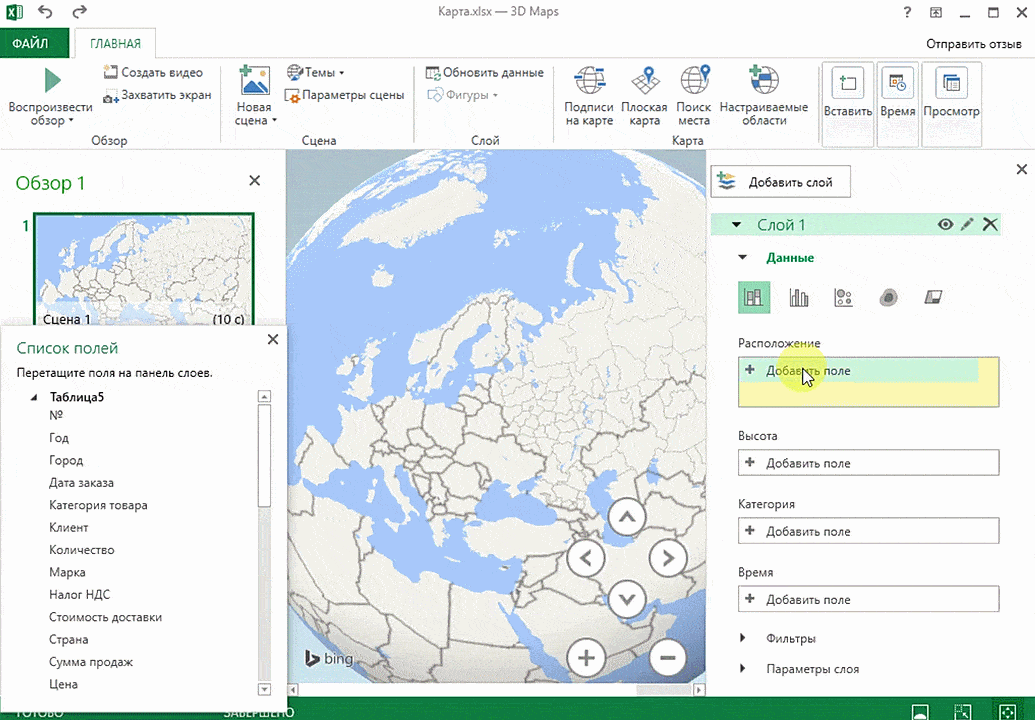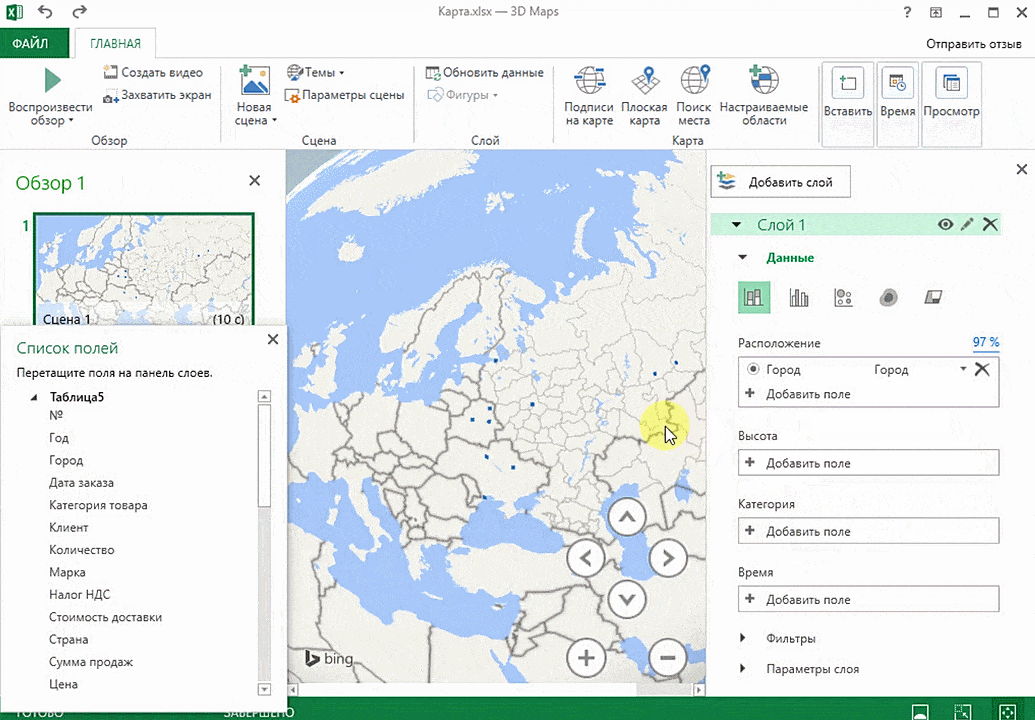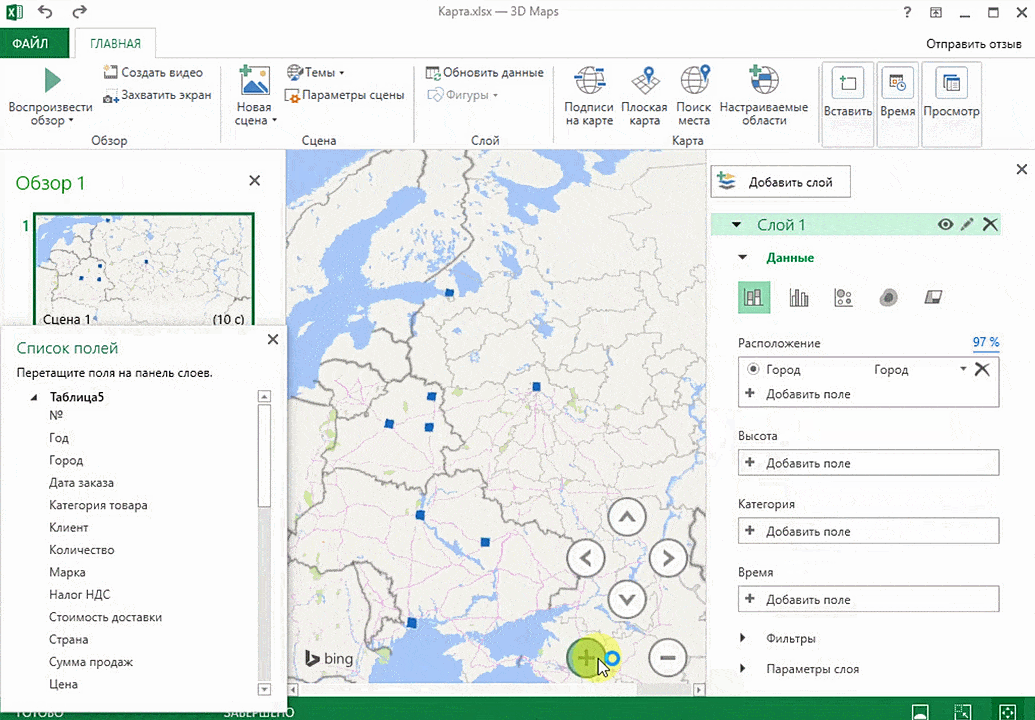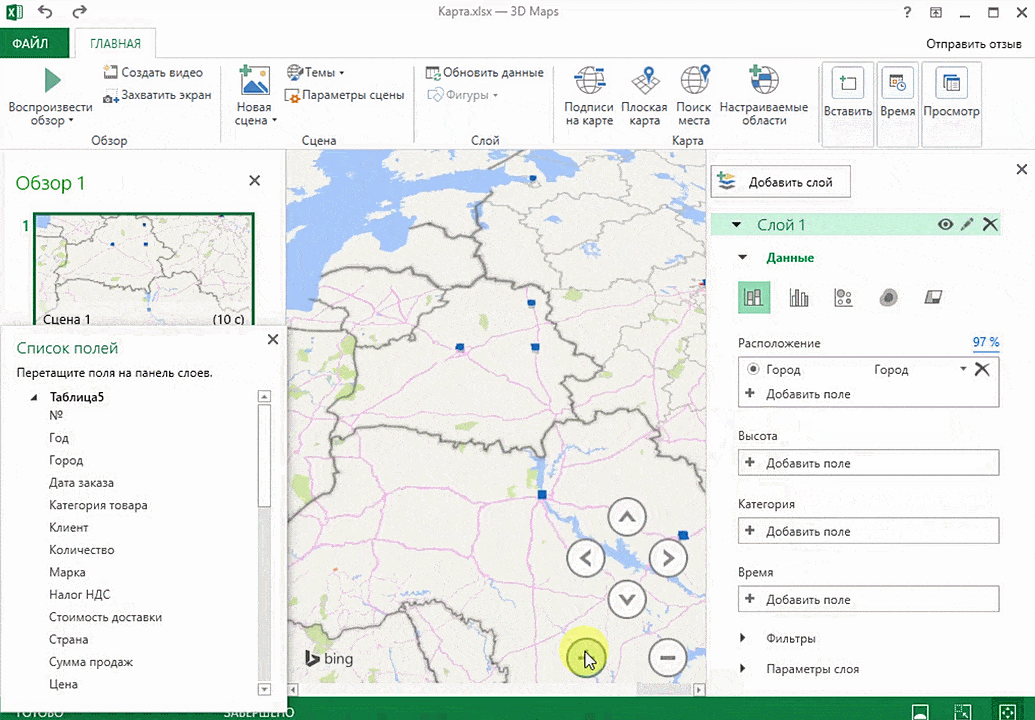
Также можно воспользоваться круговой диаграммой, которая является намного более информативной в некоторых случаях. От того, какая общая сумма по величине, зависит размер круга.
Лист прогноза в Excel
Нередко бизнес-процессы зависят от сезонных особенностей. И такие факторы надо обязательно принимать в учет на этапе планирования. Для этого существует специальный инструмент Excel, который понравится вам своей высокой точностью. Он значительно более функциональный, чем все описанные выше методы, какими бы отличными они ни были. Точно так же, очень широкой является сфера его использования – коммерческие, финансовые, маркетинговые и даже государственные структуры.
Важно:
чтобы рассчитать прогноз, необходимо получить информацию за предыдущее время. От того, насколько долгосрочные данные, зависит качество прогнозирования. Рекомендуется иметь данные, которые разбиты по одинаковым интервалам (например, поквартально или помесячно).
Как работать с листом прогноза
Чтобы работать с листом прогноза, необходимо выполнять следующие действия:
- Откройте файл, в котором содержится большой объем информации по тем показателям, которые нам надо проанализировать. Например, в течение прошлого года (хотя чем больше, тем лучше).
- Выделите две строки с информацией.
- Перейдите в меню «Данные», и там кликните по кнопке «Лист прогноза».
- После этого откроется диалог, в котором можно выбрать тип визуального представления прогноза: график или гистограмма. Выберите тот, который подходит под вашу ситуацию.
- Установите дату, когда прогноз должен закончиться.
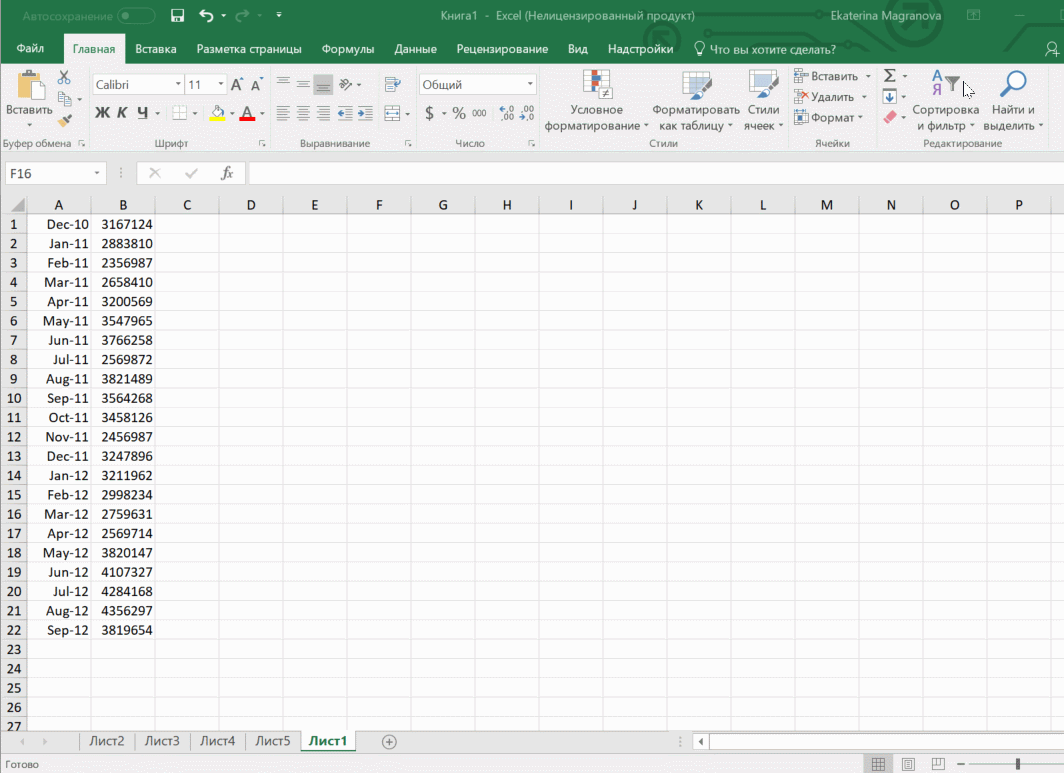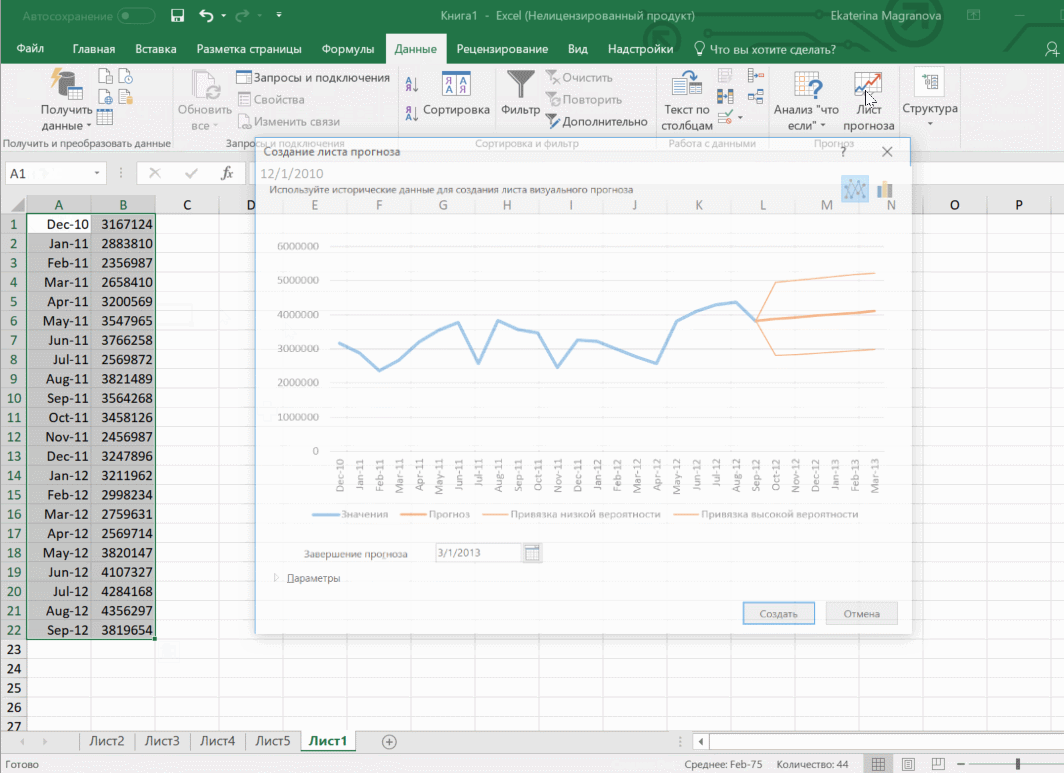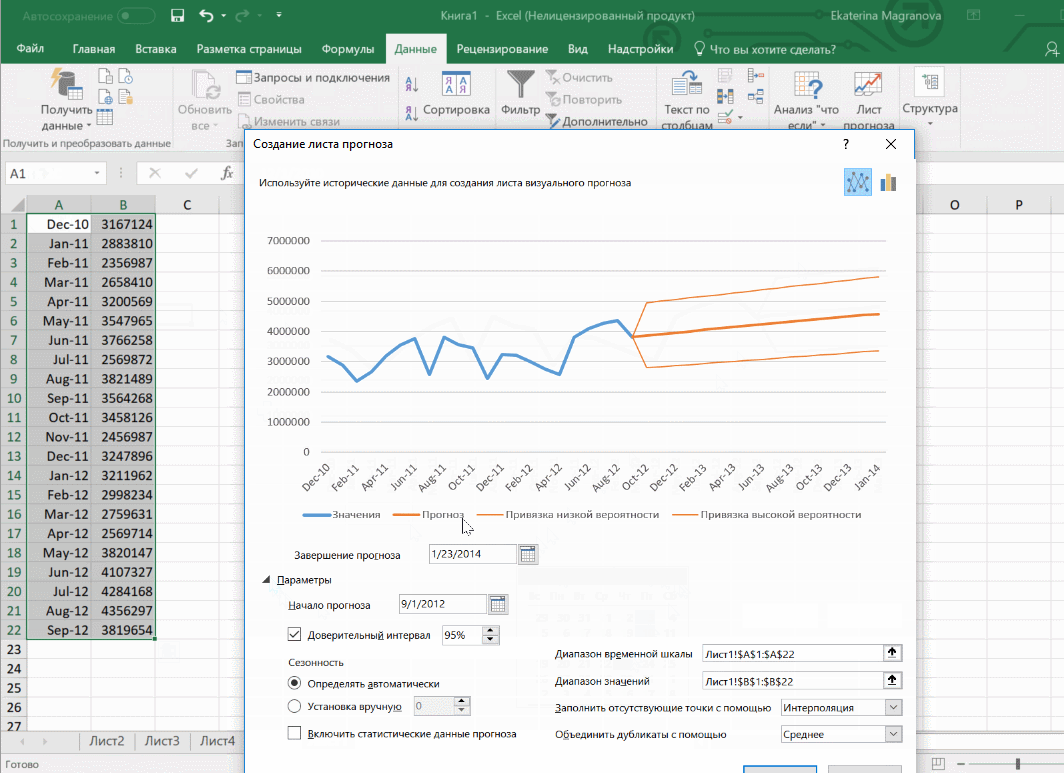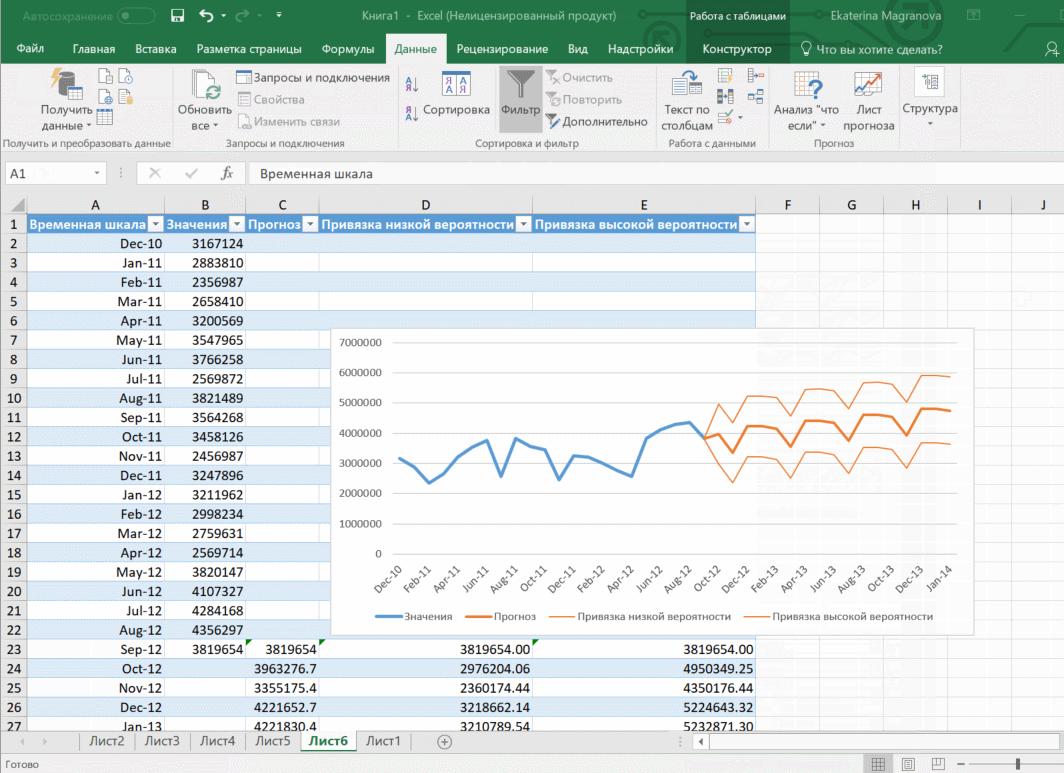
В приводимом нами ниже примере даются сведения за три года – 2011-2013. При этом рекомендуется указывать временные промежутки, а не конкретные числа. То есть, лучше писать март 2013, а не конкретное число типа 7 марта 2013 года. Чтобы исходя из этих данных получить прогноз на 2014 год необходимо получить данных, расположенные в рядах с датой и показателями, которые были на этот момент. Выделяем эти строки.
Затем переходим на вкладку «Данные» и ищем группу «Прогноз». После этого переходим в меню «Лист прогноза». После этого появится окно, в котором снова выбираем способ представления прогноза, а затем устанавливаем дату, к которой прогноз должен быть закончен. После этого нажимаем на «Создать», после чего получаем три варианта прогноза (показываются оранжевой линией).
Быстрый анализ в Excel
Предыдущий способ действительно хорош, потому что позволяет составлять реальные прогнозы, основываясь на статистических показателях. Но этот метод позволяет фактически проводить полноценную бизнес-аналитику. Очень классно, что эта возможность создана максимально эргономичной, поскольку для достижения желаемого результата необходимо совершить буквально несколько действий. Никаких ручных подсчетов, записи каких-либо формул. Достаточно просто выбрать диапазон, который будет анализироваться и задать конечную цель.
Есть возможность прямо в ячейке создавать самые разные диаграммы и микрографики.
Как работать
Итак, чтобы работать, нам надо надо открыть файл, в котором содержится тот набор данных, который надо анализировать и выделить соответствующий диапазон. После того, как мы его выделим, у нас автоматически появится кнопка, дающая возможность составить итоги или же выполнить набор других действий. Называется она быстрым анализом. Также мы можем определить суммы, которые автоматически будут проставлены внизу. Более наглядно посмотреть, как это работает, можете на этой анимации.
Функция быстрого анализа позволяет также по-разному форматировать получившиеся данные. А определить, какие значения больше или меньше, можно непосредственно в ячейках гистограммы, которая появляется после того, как мы настроим этот инструмент. 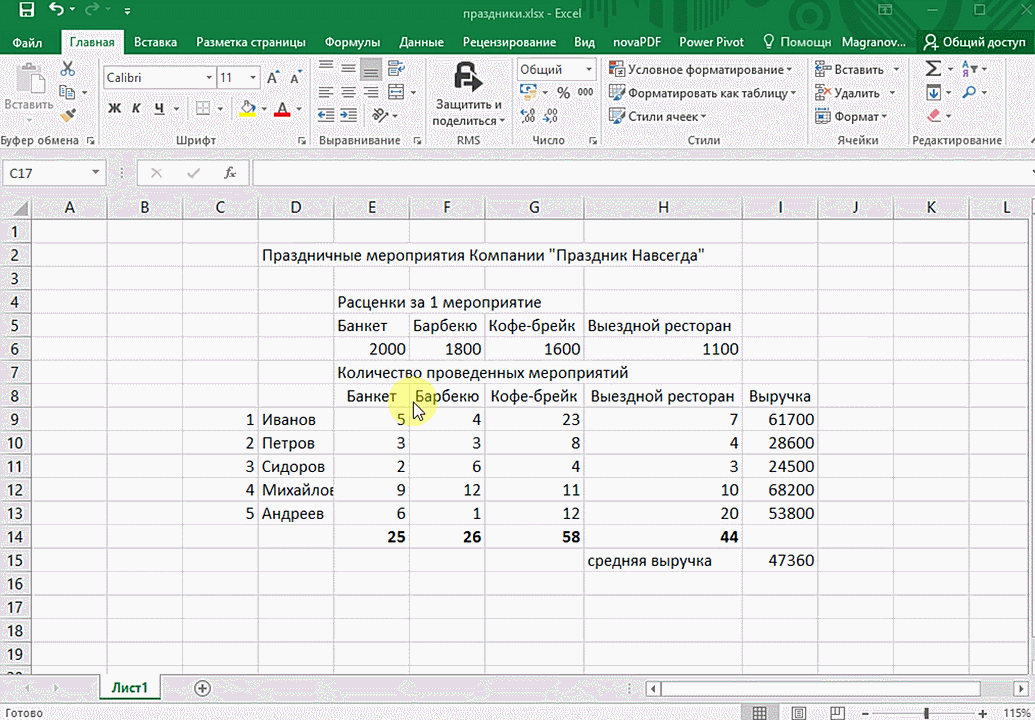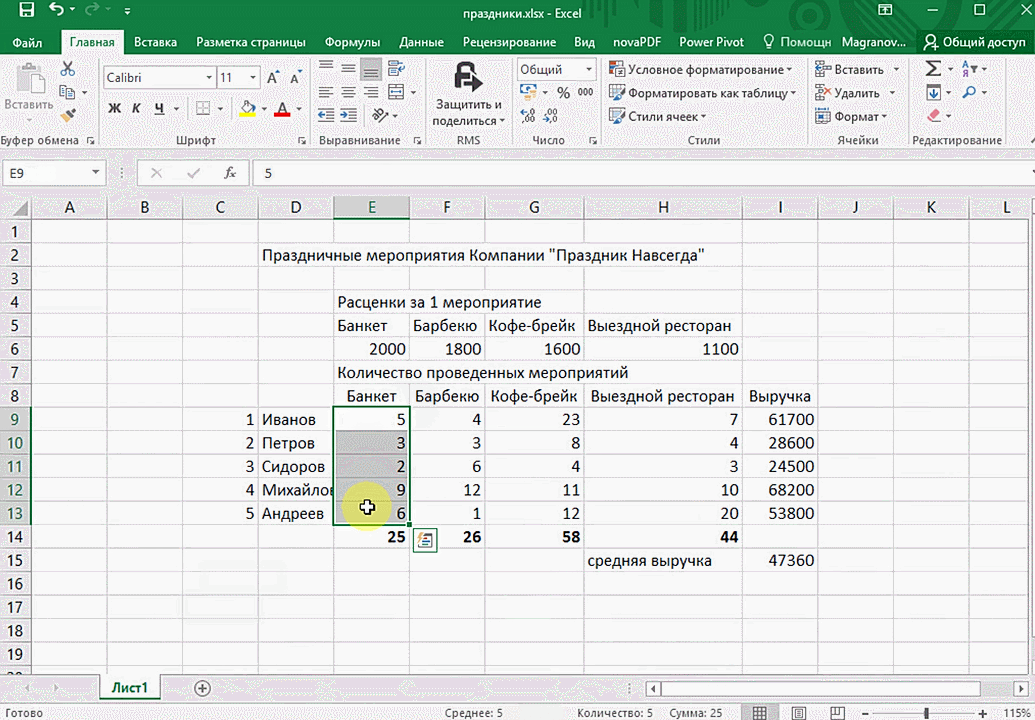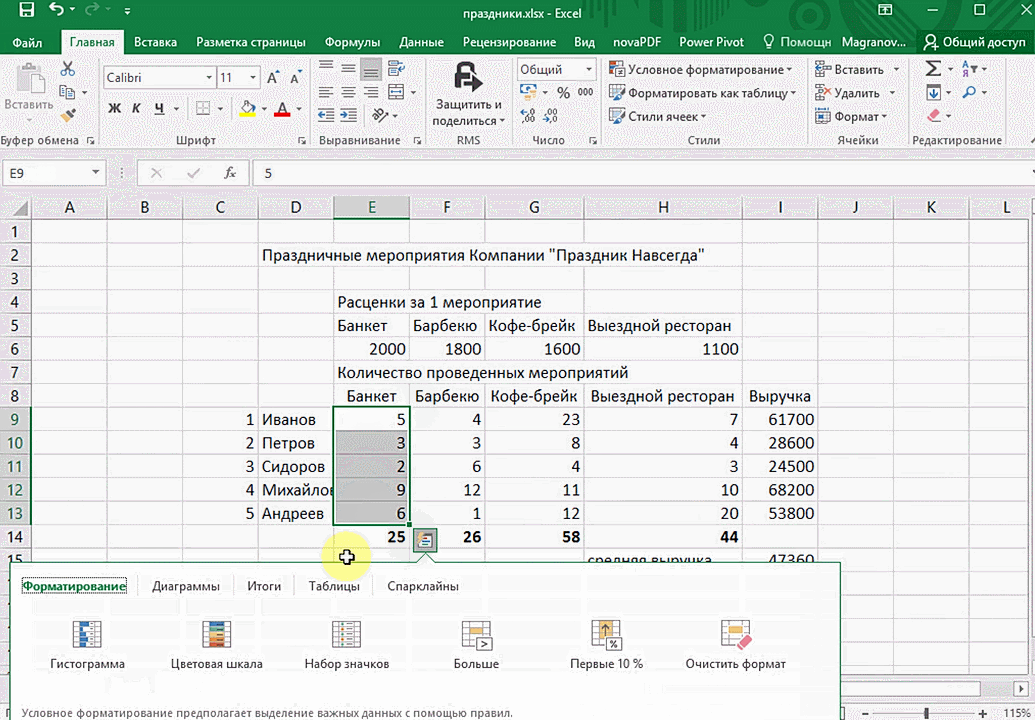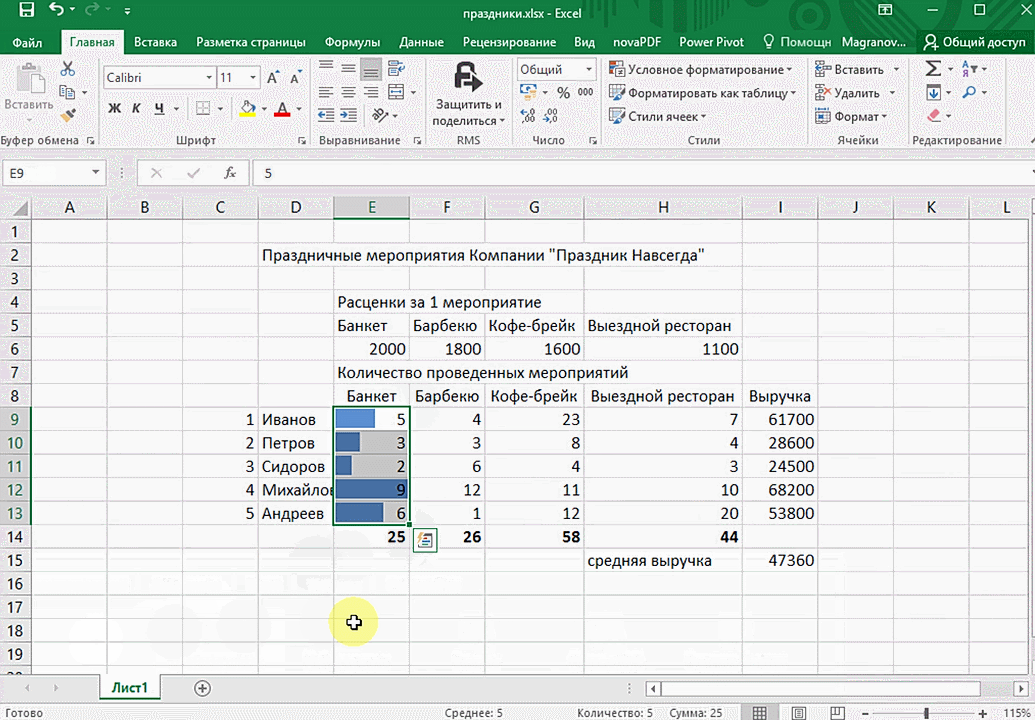
Также пользователь может поставить самые разные маркеры, которые обозначают большие и меньшие значения относительно тех, которые есть в выборке. Так, зеленым цветом будут показываться самые большие значения, а красным – наиболее маленькие.
Очень хочется верить, что эти приемы позволят вам значительно повысить эффективность вашей работы с электронными таблицами и максимально быстро добиться всего, что вы желаете. Как видим, эта программа для работы с электронными таблицами дает очень широкие возможности даже в стандартном функционале. А что уже говорить про дополнения, которых очень много на просторах интернета. Важно только обратить внимание, что все аддоны должны быть тщательно проверены на вирусы, потому что модули, написанные другими людьми, могут содержать вредоносный код. Если же надстройки разработаны компанией Майкрософт, то ее можно использовать смело.
Пакет анализа от Майкрософт – очень функциональная надстройка, которая делает пользователя настоящим профессионалом. Она позволяет выполнить почти любую обработку количественных данных, но она довольно сложная для начинающего пользователя. На официальном сайте справки Майкрософт есть детальная инструкция по тому, как использовать разные виды анализа с помощью этого пакета.
Оцените качество статьи. Нам важно ваше мнение:

Открытый курс машинного обучения mlcourse.ai
сообщества OpenDataScience
– это сбалансированный по теории и практике курс, дающий как знания, так и навыки (необходимые, но не достаточные) машинного обучения уровня Junior Data Scientist. Нечасто встретите и подробное описание математики, стоящей за используемыми алгоритмами, и соревнования Kaggle Inclass, и примеры бизнес-применения машинного обучения в одном курсе. С 2017 по 2019 годы Юрий Кашницкий
yorko
и большая команда ODS проводили живые запуски курса дважды в год – с домашними заданиями, соревнованиями и общим рейтингом учаcтников (имена героев запечатлены тут
). Сейчас курс в режиме самостоятельного прохождения.
Курс состоит из:
- 10 статей тут на Хабре. Впрочем, актуальный обновляемый материал – на английском на сайте mlcourse.ai
; - 10 лекций ( Youtube
-плейлист на русском (2017 г.) + более свежие лекции
на англ. (2018 г.)), подробное описание каждой темы – в этой
статье; - воспроизводимых материалов (Jupyter notebooks) в репозитории
mlcourse.ai (обновляются) и в виде Kaggle Dataset
(не обновляется, но зато тут нужен только браузер); - отличных соревнований Kaggle Inclass (не на “стаканье xgboost-ов”, а на построение признаков);
- демо-версий домашних заданий по каждой теме;
- расширенных домашних заданий
по каждой теме (только на англ.), доступных по подписке на Patreon ( “Bonus Assignments” tier
).
Список статей серии
План этой статьи
О курсе
Мы не ставим себе задачу разработать еще один исчерпывающий
вводный курс по машинному обучению или анализу данных (т.е. это не замена специализации Яндекса и МФТИ, дополнительному образованию ВШЭ и прочим фундаментальным онлайн- и оффлайн-программам и книжкам). Цель этой серии статей — быстро освежить имеющиеся у вас знания или помочь найти темы для дальнейшего изучения. Подход примерно как у авторов книги Deep Learning
, которая начинается с обзора математики и основ машинного обучения — краткого, максимально ёмкого и с обилием ссылок на источники.
- базовую математику (математический анализ, линейную алгебру, оптимизацию, теорвер и статистику) можно повторить по этим
конспектам Yandex & MIPT (делимся с разрешения). Кратко, на русском – то что надо. Если подробно, то матан – Кудрявцев, линал – Кострикин, оптимизация – Boyd (англ.), теорвер и статистика – Кибзун. Плюс отличные онлайн-курсы МФТИ и ВШЭ на Coursera; - по Python хватит небольшого интерактивного туториала на Datacamp или этого репозитория
по Python и базовым алгоритмам и структурам данных. Что-то более продвинутое – это, например, курс
питерского Computer Science Center; - что касается машинного обучения, то есть классический (но слегка устаревший) курс Andrew Ng “Machine Learning”(Stanford, Coursera). На русском языке есть отличная специализация МФТИ и Яндекса «Машинное обучение и анализ данных». А вот и лучшие книги: “Pattern recognition and Machine Learning” (Bishop), “Machine Learning: A Probabilistic Perspective ” (Murphy), “The elements of statistical learning” (Hastie, Tibshirani, Friedman), “Deep Learning” (Goodfellow, Bengio, Courville). Книга Goodfellow начинается с обзора математики и понятного и интересного введения в машинное обучение и внутреннее устройство его алгоритмов. Приятно, что теперь про глубокое обучение есть книга и на русском языке – “Глубокое обучение: погружение в мир нейронных сетей” (Николенко С. И., Кадурин А. А., Архангельская Е. О.).
Также про курс рассказано в этом
анонсе.
Какое ПО нужно
Для прохождения курса нужен ряд Python-пакетов, большинство из них есть в сборке Anaconda
с Python 3.6. Чуть позже понадобятся и другие библиотеки, об этом будет сказано дополнительно. Полный список можно посмотреть в Dockerfile
.
Также можно воспользоваться Docker-контейнером, в котором все необходимое ПО уже установлено. Подробности – на странице
Wiki репозитория
.
Домашние задания в курсе
Каждая статья сопровождается домашним заданием в виде Jupyter Notebook
, в который надо дописать код, и на основе этого выбрать правильный ответ в Google-форме. Примеры домашних заданий приведены в статьях серии (в конце).
Демонстрация основных методов Pandas
Весь код можно воспроизвести в этом
Jupyter notebook. Но актуальная обновляемая версия – только на английском
.
Pandas
— это библиотека Python, предоставляющая широкие возможности для анализа данных. Данные, с которыми работают датасаентисты, часто хранятся в форме табличек — например, в форматах .csv, .tsv или .xlsx. С помощью библиотеки Pandas такие табличные данные очень удобно загружать, обрабатывать и анализировать с помощью SQL-подобных запросов. А в связке с библиотеками Matplotlib и Seaborn Pandas предоставляет широкие возможности визуального анализа табличных данных.
Основными структурами данных в Pandas являются классы Series
и DataFrame
. Первый из них представляет собой одномерный индексированный массив данных некоторого фиксированного типа. Второй – это двухмерная структура данных, представляющая собой таблицу, каждый столбец которой содержит данные одного типа. Можно представлять её как словарь объектов типа Series. Структура DataFrame отлично подходит для представления реальных данных: строки соответствуют признаковым описаниям отдельных объектов, а столбцы соответствуют признакам.
# импортируем Pandas и Numpy
import pandas as pd
import numpy as np Будем показывать основные методы в деле, анализируя набор данных
по оттоку клиентов телеком-оператора (скачивать не нужно, он есть в репозитории). Прочитаем данные (метод read_csv
) и посмотрим на первые 5 строк с помощью метода head
:
df = pd.read_csv('../../data/telecom_churn.csv') df.head() 
Про вывод датафрейма в тетрадке Jupyter
В Jupyter-ноутбуках датафреймы Pandas выводятся в виде вот таких красивых табличек, и print(df.head())
выглядит хуже.
По умолчанию Pandas выводит всего 20 столбцов и 60 строк, поэтому если ваш датафрейм больше, воспользуйтесь функцией set_option
:
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100) Каждая строка представляет собой одного клиента – это объект
исследования.
Столбцы – признаки
объекта.
Целевая переменная: Churn
– Признак оттока, бинарный признак (1 – потеря клиента, то есть отток). Потом мы будем строить модели, прогнозирующие этот признак по остальным, поэтому мы и назвали его целевым.
Посмотрим на размер данных, названия признаков и их типы.
print(df.shape) (3333, 20) Видим, что в таблице 3333 строки и 20 столбцов. Выведем названия столбцов:
print(df.columns) Index(['State', 'Account length', 'Area code', 'International plan', 'Voice mail plan', 'Number vmail messages', 'Total day minutes', 'Total day calls', 'Total day charge', 'Total eve minutes', 'Total eve calls', 'Total eve charge', 'Total night minutes', 'Total night calls', 'Total night charge', 'Total intl minutes', 'Total intl calls', 'Total intl charge', 'Customer service calls', 'Churn'], dtype='object') Чтобы посмотреть общую информацию по датафрейму и всем признакам, воспользуемся методом info
:
print(df.info()) <class 'pandas.core.frame.DataFrame'>
RangeIndex: 3333 entries, 0 to 3332
Data columns (total 20 columns):
State 3333 non-null object
Account length 3333 non-null int64
Area code 3333 non-null int64
International plan 3333 non-null object
Voice mail plan 3333 non-null object
Number vmail messages 3333 non-null int64
Total day minutes 3333 non-null float64
Total day calls 3333 non-null int64
Total day charge 3333 non-null float64
Total eve minutes 3333 non-null float64
Total eve calls 3333 non-null int64
Total eve charge 3333 non-null float64
Total night minutes 3333 non-null float64
Total night calls 3333 non-null int64
Total night charge 3333 non-null float64
Total intl minutes 3333 non-null float64
Total intl calls 3333 non-null int64
Total intl charge 3333 non-null float64
Customer service calls 3333 non-null int64
Churn 3333 non-null bool
dtypes: bool, float64, int64, objectmemory usage: 498.1+ KB
None
bool
, int64
, float64
и object
— это типы признаков. Видим, что 1 признак — логический (bool), 3 признака имеют тип object и 16 признаков — числовые. Также с помощью метода info
удобно быстро посмотреть на пропуски в данных, в нашем случае их нет, в каждом столбце по 3333 наблюдения.
Изменить тип колонки
можно с помощью метода astype
. Применим этот метод к признаку Churn
и переведём его в int64
:
df['Churn'] = df['Churn'].astype('int64') Метод describe
показывает основные статистические характеристики данных по каждому числовому признаку (типы int64
и float64
): число непропущенных значений, среднее, стандартное отклонение, диапазон, медиану, 0.25 и 0.75 квартили.
df.describe() 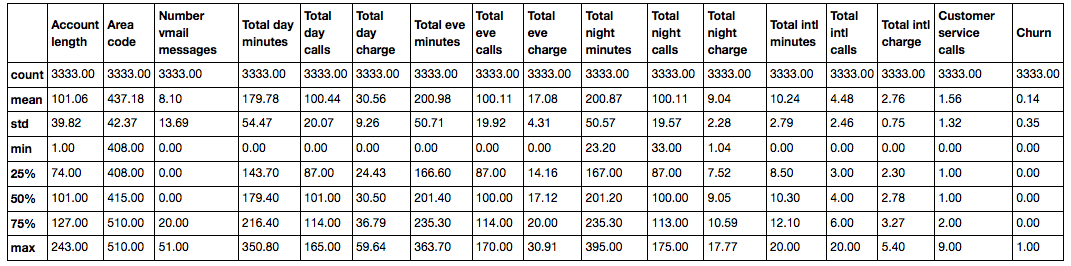
Чтобы посмотреть статистику по нечисловым признакам, нужно явно указать интересующие нас типы в параметре include
.
df.describe(include=['object', 'bool']) Для категориальных (тип object
) и булевых (тип bool
) признаков можно воспользоваться методом value_counts
. Посмотрим на распределение данных по нашей целевой переменной — Churn
:
df['Churn'].value_counts() 0 2850
1 483
Name: Churn, dtype: int64 2850 пользователей из 3333 — лояльные, значение переменной Churn
у них — 0
.
Посмотрим на распределение пользователей по переменной Area code
. Укажем значение параметра normalize=True
, чтобы посмотреть не абсолютные частоты, а относительные.
df['Area code'].value_counts(normalize=True) 415 0.496550
510 0.252025
408 0.251425
Name: Area code, dtype: float64 Сортировка
df.sort_values(by='Total day charge', ascending=False).head() 
Сортировать можно и по группе столбцов:
df.sort_values(by=['Churn', 'Total day charge'], ascending=[True, False]).head() 
Индексация и извлечение данных
DataFrame можно индексировать по-разному. В связи с этим рассмотрим различные способы индексации и извлечения нужных нам данных из датафрейма на примере простых вопросов.
df['Churn'].mean(). # выводит: 0.14491449144914492 14,5% — довольно плохой показатель для компании, с таким процентом оттока можно и разориться.
Воспользуемся этим для ответа на вопрос: каковы средние значения числовых признаков среди нелояльных пользователей?
df[df['Churn'] == 1].mean() Account length 102.664596
Number vmail messages 5.115942
Total day minutes 206.914079
Total day calls 101.335404
Total day charge 35.175921
Total eve minutes 212.410145
Total eve calls 100.561077
Total eve charge 18.054969
Total night minutes 205.231677
Total night calls 100.399586
Total night charge 9.235528
Total intl minutes 10.700000
Total intl calls 4.163561
Total intl charge 2.889545
Customer service calls 2.229814
Churn 1.000000
dtype: float64 Скомбинировав предыдущие два вида индексации, ответим на вопрос: сколько в среднем в течение дня разговаривают по телефону нелояльные пользователи
?
df[df['Churn'] == 1]['Total day minutes'].mean() # выводит: 206.91407867494823 Какова максимальная длина международных звонков среди лояльных пользователей ( Churn == 0
), не пользующихся услугой международного роуминга ( 'International plan' == 'No'
)?
df[(df['Churn'] == 0) & (df['International plan'] == 'No')]['Total intl minutes'].max() # выводит: 18.899999999999999 Датафреймы можно индексировать как по названию столбца или строки, так и по порядковому номеру. Для индексации по названию
используется метод loc
, по номеру
— iloc
.
В первом случае мы говорим «передай нам значения для id строк от 0 до 5 и для столбцов от State до Area code»
, а во втором — «передай нам значения первых пяти
строк в первых трёх столбцах»
.
Хозяйке на заметку:
когда мы передаём slice object в iloc
, датафрейм слайсится как обычно. Однако в случае с loc
учитываются и начало, и конец слайса ( ссылка на документацию
).
df.loc[0:5, 'State':'Area code'] df.iloc[0:5, 0:3] df[-1:] 
Применение функций к ячейкам, столбцам и строкам
Применение функции к каждому столбцу: apply
df.apply(np.max) State WY
Account length 243
Area code 510
International plan Yes
Voice mail plan Yes
Number vmail messages 51
Total day minutes 350.8
Total day calls 165
Total day charge 59.64
Total eve minutes 363.7
Total eve calls 170
Total eve charge 30.91
Total night minutes 395
Total night calls 175
Total night charge 17.77
Total intl minutes 20
Total intl calls 20
Total intl charge 5.4
Customer service calls 9
Churn True
dtype: object Метод apply
можно использовать и для того, чтобы применить функцию к каждой строке. Для этого нужно указать axis=1
.
Применение функции к каждой ячейке столбца: map
d = {'No' : False, 'Yes' : True}
df['International plan'] = df['International plan'].map(d)
df.head() 
Аналогичную операцию можно провернуть с помощью метода replace
:
df = df.replace({'Voice mail plan': d})
df.head() 
Группировка данных
В общем случае группировка данных в Pandas выглядит следующим образом:
df.groupby(by=grouping_columns)[columns_to_show].function() - К датафрейму применяется метод
groupby
, который разделяет данные поgrouping_columns
– признаку или набору признаков. - Выбираем нужные нам столбцы (
columns_to_show
). - К полученным группам применяется функция или несколько функций.
Группирование данных в зависимости от значения признака Churn
и вывод статистик по трём столбцам в каждой группе.
columns_to_show = ['Total day minutes', 'Total eve minutes', 'Total night minutes']
df.groupby(['Churn'])[columns_to_show].describe(percentiles=[]) 
Сделаем то же самое, но немного по-другому, передав в agg
список функций:
columns_to_show = ['Total day minutes', 'Total eve minutes', 'Total night minutes']
df.groupby(['Churn'])[columns_to_show].agg([np.mean, np.std, np.min, np.max]) 
Сводные таблицы
Допустим, мы хотим посмотреть, как наблюдения в нашей выборке распределены в контексте двух признаков — Churn
и International plan
. Для этого мы можем построить таблицу сопряженности
, воспользовавшись методом crosstab
:
pd.crosstab(df['Churn'], df['International plan']) pd.crosstab(df['Churn'], df['Voice mail plan'], normalize=True) Мы видим, что большинство пользователей лояльны и при этом пользуются дополнительными услугами (международного роуминга / голосовой почты).
Продвинутые пользователи Excel наверняка вспомнят о такой фиче, как сводные таблицы
(pivot tables). В Pandas за сводные таблицы отвечает метод pivot_table
, который принимает в качестве параметров:
-
values
– список переменных, по которым требуется рассчитать нужные статистики, -
index
– список переменных, по которым нужно сгруппировать данные, -
aggfunc
— то, что нам, собственно, нужно посчитать по группам — сумму, среднее, максимум, минимум или что-то ещё.
Давайте посмотрим среднее число дневных, вечерних и ночных звонков для разных Area code:
df.pivot_table(['Total day calls', 'Total eve calls', 'Total night calls'],
['Area code'], aggfunc='mean').head Преобразование датафреймов
Как и многое другое в Pandas, добавление столбцов в DataFrame осуществимо несколькими способами.
Например, мы хотим посчитать общее количество звонков для всех пользователей. Создадим объект total_calls
типа Series и вставим его в датафрейм:
total_calls = df['Total day calls'] + df['Total eve calls'] + \ df['Total night calls'] + df['Total intl calls']
df.insert(loc=len(df.columns), column='Total calls', value=total_calls)
# loc - номер столбца, после которого нужно вставить данный Series
# мы указали len(df.columns), чтобы вставить его в самом конце
df.head() 
Добавить столбец из имеющихся можно и проще, не создавая промежуточных Series:
df['Total charge'] = df['Total day charge'] + df['Total eve charge'] + df['Total night charge'] + df['Total intl charge']
df.head() 
Чтобы удалить столбцы или строки, воспользуйтесь методом drop
, передавая в качестве аргумента нужные индексы и требуемое значение параметра axis
( 1
, если удаляете столбцы, и ничего или 0
, если удаляете строки):
# избавляемся от созданных только что столбцов
df = df.drop(['Total charge', 'Total calls'], axis=1)
df.drop([1, 2]).head() # а вот так можно удалить строчки 
Первые попытки прогнозирования оттока
Посмотрим, как отток связан с признаком “Подключение международного роуминга” (International plan)
. Сделаем это с помощью сводной таблички crosstab
, а также путем иллюстрации с Seaborn (как именно строить такие картинки и анализировать с их помощью графики – материал следующей статьи).
pd.crosstab(df['Churn'], df['International plan'], margins=True) 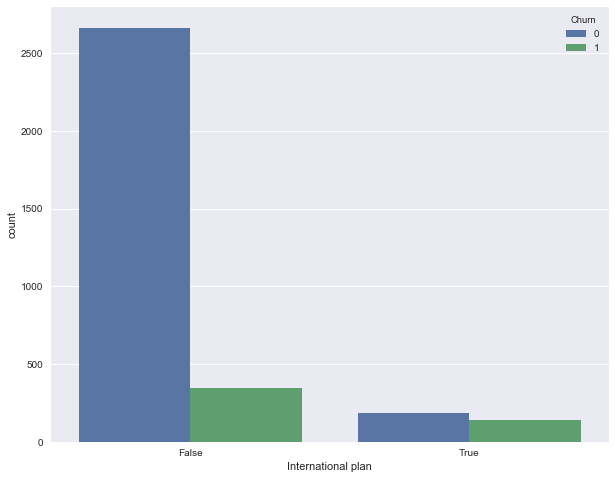
Видим, что когда роуминг подключен, доля оттока намного выше – интересное наблюдение! Возможно, большие и плохо контролируемые траты в роуминге очень конфликтогенны и приводят к недовольству клиентов телеком-оператора и, соответственно, к их оттоку.
Далее посмотрим на еще один важный признак – “Число обращений в сервисный центр” (Customer service calls)
. Также построим сводную таблицу и картинку.
pd.crosstab(df['Churn'], df['Customer service calls'], margins=True) 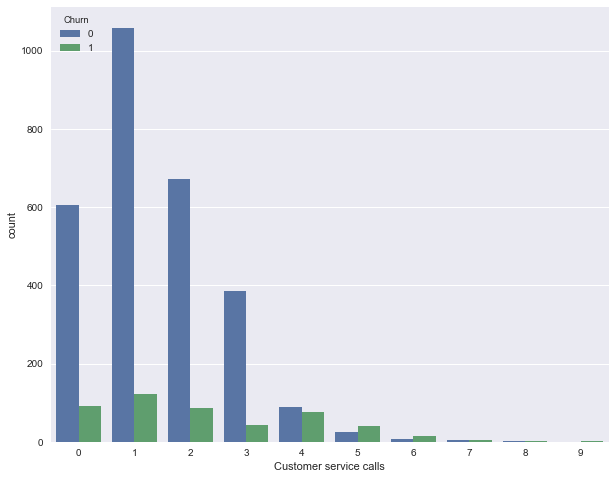
Может быть, по сводной табличке это не так хорошо видно (или скучно ползать взглядом по строчкам с цифрами), а вот картинка красноречиво свидетельствует о том, что доля оттока сильно возрастает начиная с 4 звонков в сервисный центр.
Добавим теперь в наш DataFrame бинарный признак — результат сравнения Customer service calls > 3
. И еще раз посмотрим, как он связан с оттоком.
df['Many_service_calls'] = (df['Customer service calls'] > 3).astype('int')
pd.crosstab(df['Many_service_calls'], df['Churn'], margins=True) 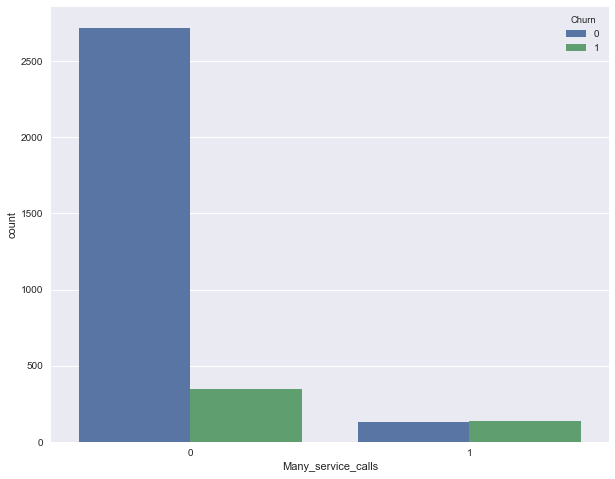
Объединим рассмотренные выше условия и построим сводную табличку для этого объединения и оттока.
pd.crosstab(df['Many_service_calls'] & df['International plan'] , df['Churn']) Значит, прогнозируя отток клиента в случае, когда число звонков в сервисный центр больше 3 и подключен роуминг (и прогнозируя лояльность – в противном случае), можно ожидать около 85.8% правильных попаданий (ошибаемся всего 464 + 9 раз). Эти 85.8%, которые мы получили с помощью очень простых рассуждений – это неплохая отправная точка ( baseline
) для дальнейших моделей машинного обучения, которые мы будем строить.
В целом до появления машинного обучения процесс анализа данных выглядел примерно так. Прорезюмируем:
- Доля лояльных клиентов в выборке – 85.5%. Самая наивная модель, ответ которой “клиент всегда лоялен” на подобных данных будет угадывать примерно в 85.5% случаев. То есть доли правильных ответов ( accuracy
) последующих моделей должны быть как минимум не меньше, а лучше, значительно выше этой цифры; - С помощью простого прогноза, который условно можно выразить такой формулой: “International plan = True & Customer Service calls > 3 => Churn = 1, else Churn = 0”, можно ожидать долю угадываний 85.8%, что еще чуть выше 85.5%. Впоследствии мы поговорим о деревьях решений и разберемся, как находить подобные правила автоматически на основе только входных данных;
- Эти два бейзлайна мы получили без всякого машинного обучения, и они служат отправной точной для наших последующих моделей. Если окажется, что мы громадными усилиями увеличиваем долю правильных ответов всего, скажем, на 0.5%, то возможно, мы что-то делаем не так, и достаточно ограничиться простой моделью из двух условий;
- Перед обучением сложных моделей рекомендуется немного покрутить данные и проверить простые предположения. Более того, в бизнес-приложениях машинного обучения чаще всего начинают именно с простых решений, а потом экспериментируют с их усложнениями.
Домашнее задание №1
Для разминки/подготовки предлагается поанализировать демографические данные с помощью Pandas. Надо заполнить недостающий код в Jupyter-заготовке
и выбрать правильные ответы в веб-форме
(там же найдете и решение).
Актуальные и обновляемые версии демо-заданий – на английском на сайте курса, вот первое задание
. Также по подписке на Patreon ( “Bonus Assignments” tier
) доступны расширенные домашние задания
по каждой теме (только на англ.).
Обзор полезных ресурсов
- Видеозапись
лекции по мотивам этой статьи - В первую очередь, конечно же, официальная документация Pandas
. В частности, рекомендуем короткое введение 10 minutes to pandas - PDF-шпаргалка по библиотеке
- Презентация Александра Дьяконова «Знакомство с Pandas»
- Серия
постов “Modern Pandas” (на английском языке) - На гитхабе есть подборка упражнений
по Pandas и еще один
полезный репозиторий (на английском языке) “Effective Pandas” - scipy-lectures.org
— учебник по работе с Pandas, NumPy, Matplotlib и scikit-learn - Pandas From The Ground Up
– видео с PyCon 2015 - Перевод этой статьи на английский – Medium story
Статья написана в соавторстве с yorko
(Юрием Кашницким).
Учимся анализировать — полный цикл
Всем привет! Долго собирался выложить данный пост и вот настал момент = )
Контент будет ориентирован на новичков в анализе данных, ниже мы с Вами рассмотрим статистику работающих и безработных людей, поставим цели и проверим гипотезы.
Язык программирования: Python
Весь код указан с пояснениями, но если у Вас возникли вопросы – отвечу в комментариях.
“Демографическая ситуация по субъектам РФ”
Описание проекта:
Перед нами представлен набор данных, который несет в себе информацию о численности экономически активного населения, безработных, уровне безработицы и сопоставляет все эти показатели между различными возрастными группами по субьектам РФ за период 2001-2019 гг.
2.
3.
4.
План анализа данных:
aggfunc
2.
2.1. total_calls
2.2.
total_calls = df['Total day calls'] + df['Total eve calls'] + \
df['Total night calls'] + df['Total intl calls']
df.insert(loc=len(df.columns), column='Total calls', value=total_calls)
# loc - номер столбца, после которого нужно вставить данный Series
# мы указали len(df.columns), чтобы вставить его в самом конце
df.head()
2.3.
2.4.
3.
df.head()df['Total charge'] = df['Total day charge'] + df['Total eve charge'] + df['Total night charge'] + df['Total intl charge']
3.1.
3.2.
drop
axis 3.3. 1
0
3.4.
# избавляемся от созданных только что столбцов
df = df.drop(['Total charge', 'Total calls'], axis=1)
df.drop([1, 2]).head() # а вот так можно удалить строчки 3.5.
3.6.
4. values
4.1. index
4.3.
4.4.
df.pivot_table(['Total day calls', 'Total eve calls', 'Total night calls'],
['Area code'], aggfunc='mean').head
5.
5.1.
6.
territory
– наименование территории по ОКАТО
num_economactivepopulation_all
– численность экономически активного населения – всего
employed_num_all
– занятые в экономике
unemployed_num_all
– безработные
eactivity_lvl
– уровень экономической активности
employment_lvl
– уровень занятости
unemployment_lvl
– уровень безработицы
dis_unagegroup_to20
– распределение безработных в возрасте до 20 лет по регионам РФ
dis_unagegroup_20-29
– распределение безработных в возрасте от 20 до 29 лет по регионам РФ
dis_unagegroup_30-39
– распределение безработных в возрасте от 30 до 39 лет по регионам РФ
dis_unagegroup_40-49
– распределение безработных в возрасте от 40 до 49 лет по регионам РФ
dis_unagegroup_50-59
– распределение безработных в возрасте от 50 до 59 лет по регионам РФ
dis_unagegroup_60older
– распределение безработных в возрасте 60 и более лет по регионам РФ
dis_emagegroup_to20
– распределение занятых в экономике в возрасте до 20 лет по регионам РФ
dis_emagegroup_20-29
– распределение занятых в экономике в возрасте от 20 до 29 лет по регионам РФ
dis_emagegroup_30-39
– распределение занятых в экономике в возрасте от 30 до 39 лет по регионам РФ
dis_emagegroup_40-49
– распределение занятых в экономике в возрасте от 40 до 49 лет по регионам РФ
dis_emagegroup_50-59
– распределение занятых в экономике в возрасте от 50 до 59 лет по регионам РФ
dis_emagegroup_60older
– распределение занятых в экономике в возрасте 60 и более лет по регионам РФ
num_unagegroup_to20
– численность безработных в возрасте до 20 лет по регионам РФ
num_unagegroup_20-29
– численность безработных в возрасте от 20 до 29 лет по регионам РФ
num_unagegroup_30-39
– численность безработных в возрасте от 30 до 39 лет по регионам РФ
num_unagegroup_40-49
– численность безработных в возрасте от 40 до 49 лет по регионам РФ
num_unagegroup_50-59
– численность безработных в возрасте от 50 до 59 лет по регионам РФ
num_unagegroup_60older
– численность безработных в возрасте 60 и более лет по регионам РФ
num_emagegroup_to20
– численность занятых в экономике регионов РФ в возрасте до 20 лет
num_emagegroup_20-29
– численность занятых в экономике регионов РФ в возрасте от 20 до 29 лет
num_emagegroup_30-39
– численность занятых в экономике регионов РФ в возрасте от 30 до 39 лет
num_emagegroup_40-49
– численность занятых в экономике регионов РФ в возрасте от 40 до 49 лет
num_emagegroup_50-59
– численность занятых в экономике регионов РФ в возрасте от 50 до 59 лет
num_emagegroup_60older
– численность занятых в экономике регионов РФ в возрасте 60 и более лет
year
– отчетный год
Изучение общей информации
Откроем файл с данными и изучим общую информацию
# импортируем необходимые библиотеки
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy import stats as st
import warnings
warnings.filterwarnings('ignore')
# для полноценной работы со строками мы уберем ограничение строк и столбцов в отображении
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None) # присвоим переменной data нашу таблицу
data = pd.read_csv('Desktop/Датасеты/Статистические данные о занятости и безработице среди населения/data.csv')
# выведем первые пять строки нашей таблицы
data.head() 
Посмотрим на информацию по нашим столбцам.
С помощью метода info() мы можем увидеть типы каждого из столбцов.
# проверяем типы столбцов
data.info() 
Мы ознакомились с данными, с которыми в дальнейшем будем работать. Теперь перейдем к самой обработке.